ONNX

ONNX (Open Neural Network Exchange) is an open-source framework that plays a pivotal role in the field of Machine Learning Operations (MLOps) by providing a standardized format for representing and sharing deep learning models across different frameworks, libraries, and platforms. It acts as a bridge between various deep learning frameworks, making it easier to build, train, and deploy models seamlessly. ONNX is designed to enhance interoperability, speed up development, and promote innovation in the AI and machine learning domains.
Key Features of ONNX:
- Interoperability: ONNX allows models to be easily transferred between popular deep learning frameworks like TensorFlow, PyTorch, and more. This interoperability is crucial for MLOps as it enables teams to choose the best tools for specific tasks.
- Optimized Inference: ONNX Runtime, a runtime engine that supports the execution of ONNX models, is highly optimized for inference tasks. It ensures that models can be executed efficiently in production environments.
- Hardware Acceleration: ONNX can take advantage of hardware accelerators like GPUs and TPUs, making it suitable for deploying models in high-performance settings.
- Cross-Platform Compatibility: ONNX models can be deployed on various platforms, including edge devices, cloud servers, and even web browsers, making it versatile for different use cases.
ONNX in the Browser with WebGL
Now, let's focus on the specific topic for this week's session: Model Runtime on the Browser with WebGL using ONNX. This is an exciting development in the world of AI and MLOps because it allows machine learning models to be executed directly within web browsers, offering several advantages:
1. Low Latency Inference: ONNX models can be run in the browser, reducing the need for constant communication with remote servers. This results in lower latency and faster model execution, crucial for real-time applications like gaming, interactive websites, and more.
2. Privacy and Data Security: By running models locally in the browser, sensitive data can be kept on the client-side, enhancing privacy and data security. This is particularly important for applications involving personal or confidential information.
3. Offline Availability: ONNX models deployed in the browser remain accessible even without an internet connection. This is beneficial for applications that need to work in offline or intermittent connectivity scenarios.
4. Cross-Platform Compatibility: WebGL, a JavaScript API for rendering interactive 2D and 3D graphics, allows for the execution of ONNX models on a wide range of devices and platforms, including desktops, mobile phones, and VR headsets.
5. Web-Based AI: The combination of ONNX and WebGL enables the development of web-based AI applications, such as interactive demos, educational tools, and games that incorporate machine learning capabilities.
PyTorch to ONNX
pip install onnx onnxruntimeimport torch
import torch.onnx
import timmmodel = timm.create_model('resnetv2_50', pretrained=True)
model = model.eval()
model_script = torch.jit.script(model)torch.onnx.export(model_script, torch.randn(1, 3, 224, 224), "resnetv2_50.onnx", verbose=True, input_names=['input'], output_names=['output'], dynamic_axes={'input': {0: 'batch'}})Visualize ONNX Graph
https://onnxruntime.ai/docs/get-started/with-python.html
Tracing vs Scripting
Internally, [torch.onnx.export()](https://pytorch.org/docs/stable/onnx.html#torch.onnx.export) requires a [torch.jit.ScriptModule](https://pytorch.org/docs/stable/generated/torch.jit.ScriptModule.html#torch.jit.ScriptModule) rather than a [torch.nn.Module](https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module). If the passed-in model is not already a ScriptModule, export() will use tracing to convert it to one:
- Tracing: If
torch.onnx.export()is called with a Module that is not already aScriptModule, it first does the equivalent of[torch.jit.trace()](https://pytorch.org/docs/stable/generated/torch.jit.trace.html#torch.jit.trace), which executes the model once with the givenargsand records all operations that happen during that execution. This means that if your model is dynamic, e.g., changes behavior depending on input data, the exported model will not capture this dynamic behavior. We recommend examining the exported model and making sure the operators look reasonable. Tracing will unroll loops and if statements, exporting a static graph that is exactly the same as the traced run. If you want to export your model with dynamic control flow, you will need to use scripting. - Scripting: Compiling a model via scripting preserves dynamic control flow and is valid for inputs of different sizes. To use scripting:Use
[torch.jit.script()](https://pytorch.org/docs/stable/generated/torch.jit.script.html#torch.jit.script)to produce aScriptModule.Calltorch.onnx.export()with theScriptModuleas the model. Theargsare still required, but they will be used internally only to produce example outputs, so that the types and shapes of the outputs can be captured. No tracing will be performed.
ONNX Opset
https://github.com/onnx/onnx/blob/main/docs/Operators.md
An OpSet is essentially a collection or set of operators that are supported and defined by a specific version of the ONNX specification. It defines which operators are available and how they behave. In other words, an OpSet is a versioned set of operator definitions and rules.
Verifying ONNX
import onnxruntime as ort
import numpy as npTest with Random Input
ort_session = ort.InferenceSession("resnetv2_50.onnx")
ort_session.run(['output'], {'input': np.random.randn(1, 3, 224, 224).astype(np.float32)})Image Input
import onnxruntime as ort
import numpy as np
from PIL import Image
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
with open("imagenet_classes.txt", "r") as f:
classes_response = f.read()
classes_list = [line.strip() for line in classes_response.split('\n')]
ort_session = ort.InferenceSession("resnetv2_50.onnx")
output = ort_session.run(
['output'], {'input': np.random.randn(1, 3, 224, 224).astype(np.float32)})
print(f"random_output = {output}")
img = Image.open("test_image.jpeg")
img = img.convert("RGB")
img = img.resize((224, 224))
img_np = np.array(img)
print(f"image shape = {img_np.shape}")
img_np = img_np / 255.0
img_np = (img_np - mean) / std
img_np = img_np.transpose(2, 0, 1)
ort_outputs = ort_session.run(
['output'], {'input': img_np[None, ...].astype(np.float32)})
pred_class_idx = np.argmax(ort_outputs[0])
predicted_class = classes_list[pred_class_idx]
print(f"{predicted_class=}")ONNX on Browser
npx create-next-app@latestcp resnetv2_50.onnx public/page.tsx
"use client";
import { useEffect, useState } from "react";
import * as ort from "onnxruntime-web";
import ndarray from "ndarray";
import ops from "ndarray-ops";
import { softmax } from "@/utils/math/softmax-2";
import { imagenetClassesTopK } from "@/utils/imagenet";
export default function Home() {
const [selectedImage, setSelectedImage] = useState<File | null>(null);
const [resizedImage, setResizedImage] = useState("");
const [inferenceSession, setInferenceSession] =
useState<ort.InferenceSession | null>(null);
const [modelOutput, setModelOutput] = useState<
{ id: string; index: number; name: string; probability: number }[]
>([]);
useEffect(() => {
// load model
ort.InferenceSession.create("/resnetv2_50.onnx", {
executionProviders: ["webgl"],
graphOptimizationLevel: "all",
}).then((session) => setInferenceSession(session));
}, []);
useEffect(() => {
const mycode = async () => {
try {
if (!inferenceSession) return;
const image = document.createElement("img");
image.onload = async () => {
const canvas = document.createElement("canvas");
canvas.width = 224;
canvas.height = 224;
if (!canvas) return;
const canvas2DCtx = canvas.getContext("2d");
if (!canvas2DCtx) return;
canvas2DCtx.drawImage(image, 0, 0, 224, 224);
const resizedImage = canvas.toDataURL();
setResizedImage(resizedImage);
const imageData = canvas2DCtx.getImageData(
0,
0,
canvas2DCtx.canvas.width,
canvas2DCtx.canvas.height
);
const { data, width, height } = imageData;
// data processing
const dataTensor = ndarray(new Float32Array(data), [
width,
height,
4,
]);
const dataProcessedTensor = ndarray(
new Float32Array(width * height * 3),
[1, 3, width, height]
);
// permute [H, W, C] -> [B, C, H, W]
ops.assign(
dataProcessedTensor.pick(0, 0, null, null),
dataTensor.pick(null, null, 0)
);
ops.assign(
dataProcessedTensor.pick(0, 1, null, null),
dataTensor.pick(null, null, 1)
);
ops.assign(
dataProcessedTensor.pick(0, 2, null, null),
dataTensor.pick(null, null, 2)
);
// image normalization with mean and std
ops.divseq(dataProcessedTensor, 255);
ops.subseq(dataProcessedTensor.pick(0, 0, null, null), 0.485);
ops.subseq(dataProcessedTensor.pick(0, 1, null, null), 0.456);
ops.subseq(dataProcessedTensor.pick(0, 2, null, null), 0.406);
ops.divseq(dataProcessedTensor.pick(0, 0, null, null), 0.229);
ops.divseq(dataProcessedTensor.pick(0, 1, null, null), 0.224);
ops.divseq(dataProcessedTensor.pick(0, 2, null, null), 0.225);
const tensor = new ort.Tensor(
"float32",
new Float32Array(width * height * 3),
[1, 3, width, height]
);
(tensor.data as Float32Array).set(dataProcessedTensor.data);
// const randomA = Float32Array.from(result);
// const tensorA = new ort.Tensor("float32", randomA, [1, 3, 224, 224]);
const results = await inferenceSession.run({
input: tensor,
});
if (results.output) {
const res = results.output;
const output = softmax(Array.prototype.slice.call(res.data));
const topK = imagenetClassesTopK(output, 5);
setModelOutput(topK);
}
};
if (selectedImage) {
image.setAttribute("src", URL.createObjectURL(selectedImage));
}
} catch (e: any) {
console.error(e, e.toString());
}
};
if (selectedImage) {
mycode();
}
}, [inferenceSession, selectedImage]);
return (
<main className="flex min-h-screen flex-col items-center p-24 gap-y-12">
{!!!inferenceSession && "Loading Model..."}
{!!inferenceSession && (
<input
type="file"
name="myImage"
onChange={(event) => {
if (event.target.files && event.target.files.length > 0) {
const file = event.target.files[0];
console.log(event.target.files[0]);
setSelectedImage(event.target.files[0]);
}
}}
/>
)}
{resizedImage && (
// eslint-disable-next-line @next/next/no-img-element
<img src={resizedImage} alt="Resized Image" className="rounded-md" />
)}
{modelOutput.length > 0 && (
<table className="table-auto max-w-2xl w-full">
<thead>
<tr>
<th className="py-3.5 px-4 text-sm font-normal text-left rtl:text-right text-gray-500 dark:text-gray-400">
Index
</th>
<th className="py-3.5 px-4 text-sm font-normal text-left rtl:text-right text-gray-500 dark:text-gray-400">
Name
</th>
<th className="py-3.5 px-4 text-sm font-normal text-left rtl:text-right text-gray-500 dark:text-gray-400">
Probability
</th>
</tr>
</thead>
<tbody>
{modelOutput.map((m, i) => (
<tr key={i}>
<td className="px-4 py-4 text-sm text-gray-500 dark:text-gray-300 whitespace-nowrap">
{m.index}
</td>
<td className="px-4 py-4 text-sm text-gray-500 dark:text-gray-300 whitespace-nowrap">
{m.name}
</td>
<td className="px-4 py-4 text-sm text-gray-500 dark:text-gray-300 whitespace-nowrap">
{m.probability.toFixed(2)}
</td>
</tr>
))}
</tbody>
</table>
)}
</main>
);
}Let’s break it down to understand what is happening
Loading the ONNX Model
useEffect(() => {
// load model
ort.InferenceSession.create("/resnetv2_50.onnx", {
executionProviders: ["webgl"],
graphOptimizationLevel: "all",
}).then((session) => setInferenceSession(session));
}, []);executionProviders
WebAssembly backend
ONNX Runtime Web currently support all operators in ai.onnx and ai.onnx.ml.
WebGL backend
ONNX Runtime Web currently supports a subset of operators in ai.onnx operator set. See operators.md for a complete, detailed list of which ONNX operators are supported by WebGL backend.
WebGPU
https://developer.chrome.com/blog/webgpu-io2023/
Resizing the Image to 224, 224
const image = document.createElement("img");
image.onload = async () => {
const canvas = document.createElement("canvas");
canvas.width = 224;
canvas.height = 224;
if (!canvas) return;
const canvas2DCtx = canvas.getContext("2d");
if (!canvas2DCtx) return;
canvas2DCtx.drawImage(image, 0, 0, 224, 224);
const resizedImage = canvas.toDataURL();
setResizedImage(resizedImage);
const imageData = canvas2DCtx.getImageData(
0,
0,
canvas2DCtx.canvas.width,
canvas2DCtx.canvas.height
);
const { data, width, height } = imageData;Creating an empty placeholder for Preprocessed Image
// data processing
const dataTensor = ndarray(new Float32Array(data), [
width,
height,
4,
]);
const dataProcessedTensor = ndarray(
new Float32Array(width * height * 3),
[1, 3, width, height]
);HWC to BCHW
// permute [H, W, C] -> [B, C, H, W]
ops.assign(
dataProcessedTensor.pick(0, 0, null, null),
dataTensor.pick(null, null, 0)
);
ops.assign(
dataProcessedTensor.pick(0, 1, null, null),
dataTensor.pick(null, null, 1)
);
ops.assign(
dataProcessedTensor.pick(0, 2, null, null),
dataTensor.pick(null, null, 2)
);Image Standardization with Mean and Std of ImageNet
// image normalization with mean and std
ops.divseq(dataProcessedTensor, 255);
ops.subseq(dataProcessedTensor.pick(0, 0, null, null), 0.485);
ops.subseq(dataProcessedTensor.pick(0, 1, null, null), 0.456);
ops.subseq(dataProcessedTensor.pick(0, 2, null, null), 0.406);
ops.divseq(dataProcessedTensor.pick(0, 0, null, null), 0.229);
ops.divseq(dataProcessedTensor.pick(0, 1, null, null), 0.224);
ops.divseq(dataProcessedTensor.pick(0, 2, null, null), 0.225);Creating an ONNX Runtime Tensor
const tensor = new ort.Tensor(
"float32",
new Float32Array(width * height * 3),
[1, 3, width, height]
);
(tensor.data as Float32Array).set(dataProcessedTensor.data);Run Inference and Get Classname
const results = await inferenceSession.run({
input: tensor,
});
if (results.output) {
const res = results.output;
const output = softmax(Array.prototype.slice.call(res.data));
const topK = imagenetClassesTopK(output, 5);
setModelOutput(topK);
}There’s actually a lot more code involved to do simple operations that we do in python
imagenet.ts
import { imagenetClasses } from '@/config/imagenet-classes';
import _ from 'lodash';
/**
* Find top k imagenet classes
*/
export function imagenetClassesTopK(classProbabilities: any, k = 5) {
const probs =
_.isTypedArray(classProbabilities) ? Array.prototype.slice.call(classProbabilities) : classProbabilities;
const sorted = _.reverse(_.sortBy(probs.map((prob: any, index: number) => [prob, index]), probIndex => probIndex[0]));
const topK = _.take(sorted, k).map((probIndex: any) => {
const iClass = imagenetClasses[probIndex[1]];
return {
id: iClass[0],
index: parseInt(probIndex[1], 10),
name: iClass[1].replace(/_/g, ' '),
probability: probIndex[0]
};
});
return topK;
}https://github.com/satyajitghana/web-onnx-classifier
ONNX Graph Optimization: https://onnxruntime.ai/docs/performance/model-optimizations/graph-optimizations.html
Transformer Optimization Tool: https://onnxruntime.ai/docs/performance/transformers-optimization.html
package.json
{
"name": "web-onnx",
"version": "0.1.0",
"private": true,
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "next lint"
},
"dependencies": {
"@types/node": "20.4.2",
"@types/react": "18.2.15",
"@types/react-dom": "18.2.7",
"autoprefixer": "10.4.14",
"eslint": "8.45.0",
"eslint-config-next": "13.4.10",
"lodash": "^4.17.21",
"ndarray": "^1.0.19",
"ndarray-ops": "^1.2.2",
"next": "13.4.10",
"onnxruntime-web": "^1.15.1",
"postcss": "8.4.26",
"react": "18.2.0",
"react-dom": "18.2.0",
"tailwindcss": "3.3.3",
"typescript": "5.1.6"
},
"devDependencies": {
"@types/lodash": "^4.14.195",
"@types/ndarray": "^1.0.11",
"@types/ndarray-ops": "^1.2.4"
}
}npm run dev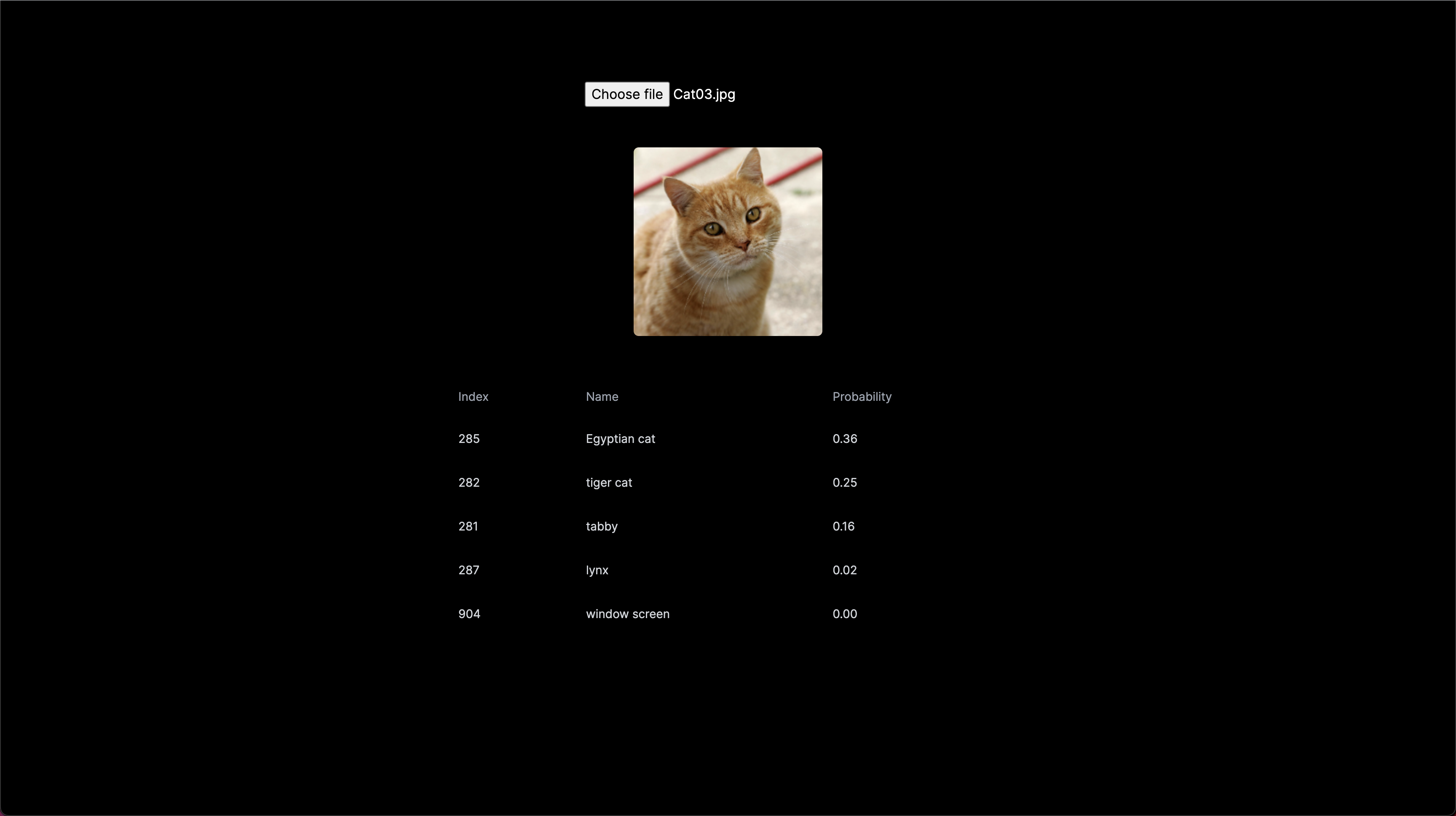
YOLOV8
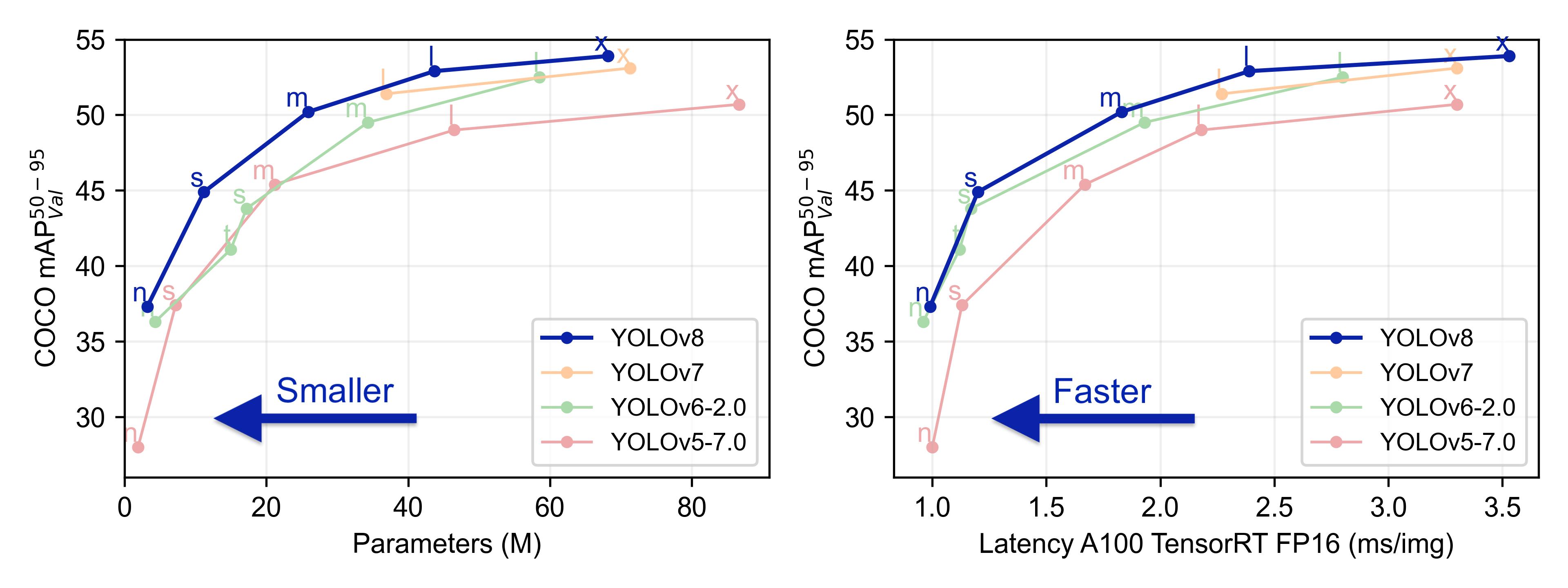
| Model | size(pixels) | mAPval50-95 | SpeedCPU ONNX(ms) | SpeedA100 TensorRT(ms) | params(M) | FLOPs(B) |
|---|---|---|---|---|---|---|
| https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8s.pt | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8m.pt | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8l.pt | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8x.pt | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
https://github.com/ultralytics/ultralytics
pip install ultralyticssudo apt update && sudo apt install libgl1from ultralytics import YOLO
# Create a new YOLO model from scratch
model = YOLO('yolov8n.yaml')
# Load a pretrained YOLO model (recommended for training)
model = YOLO('yolov8n.pt')
# Train the model using the 'coco128.yaml' dataset for 3 epochs
results = model.train(data='coco128.yaml', epochs=3)
# Evaluate the model's performance on the validation set
results = model.val()
# Perform object detection on an image using the model
results = model('https://ultralytics.com/images/bus.jpg')
# Export the model to ONNX format
success = model.export(format='onnx')Convert YOLOV8 to ONNX
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom trained
# Export the model
model.export(format='onnx')Using CLI
yolo export model=yolov8n.pt format=onnx # export official model
yolo export model=path/to/best.pt format=onnx # export custom trained modelhttps://docs.ultralytics.com/tasks/detect/#export
ONNX NMS: https://github.com/Hyuto/fun/blob/master/test-onnx-graph-surgeon/nms-onnx-v8.py
Download Models from: https://github.com/satyajitghana/web-yolo-onnx/tree/master/public/model
page.tsx
"use client";
import { useEffect, useRef, useState } from "react";
import cv from "@techstark/opencv-js";
import { Tensor, InferenceSession } from "onnxruntime-web";
import { detectImage } from "@/lib/utils";
const modelConfig = {
name: "yolov8n.onnx",
nmsModel: "nms-yolov8.onnx",
inputShape: [1, 3, 640, 640],
topK: 100,
iouThreshold: 0.45,
scoreThreshold: 0.25,
};
export default function Home() {
const [session, setSession] = useState<{
net: InferenceSession;
nms: InferenceSession;
} | null>(null);
const [loading, setLoading] = useState(true);
const [image, setImage] = useState<string | null>(null);
const inputRef = useRef<HTMLInputElement>(null);
const inputImageRef = useRef<HTMLImageElement>(null);
const canvasOutputRef = useRef<HTMLCanvasElement>(null);
const canvasInputRef = useRef<HTMLCanvasElement>(null);
cv["onRuntimeInitialized"] = async () => {
// create the YOLOv8 Model
const yolov8 = await InferenceSession.create(`/model/${modelConfig.name}`, {
executionProviders: ["wasm"],
});
// create the NMS Model
const nms = await InferenceSession.create(
`/model/${modelConfig.nmsModel}`,
{
executionProviders: ["wasm"],
}
);
const tensor = new Tensor(
"float32",
new Float32Array(modelConfig.inputShape.reduce((a, b) => a * b)),
modelConfig.inputShape
);
const res = await yolov8.run({ images: tensor });
console.log("model warm up", res);
setSession({
net: yolov8,
nms: nms,
});
setLoading(false);
};
return (
<main className="flex min-h-screen flex-col items-center justify-between p-24">
<h1 className="text-3xl">YOLOV8 - ONNX - WASM</h1>
{loading && <>Loading Model...</>}
<img
ref={inputImageRef}
src="#"
alt=""
// style={{ display: image ? "block" : "none" }}
className="hidden absolute"
onLoad={() => {
if (!inputImageRef.current || !canvasOutputRef.current) return;
if (!session) return;
detectImage(
inputImageRef.current,
canvasOutputRef.current,
session,
modelConfig.topK,
modelConfig.iouThreshold,
modelConfig.scoreThreshold,
modelConfig.inputShape
);
}}
/>
<div className="relative min-h-[640px] min-w-[640px]">
<div className="absolute flex flex-col items-center w-full justify-center z-20">
<canvas
width={modelConfig.inputShape[2]}
height={modelConfig.inputShape[3]}
ref={canvasInputRef}
className="absolute left-0 top-0 rounded-md"
/>
<canvas
width={modelConfig.inputShape[2]}
height={modelConfig.inputShape[3]}
ref={canvasOutputRef}
className="absolute left-0 top-0"
/>
</div>
</div>
<input
type="file"
ref={inputRef}
accept="image/*"
onChange={(e) => {
if (!inputImageRef.current) return;
if (e.target.files?.length) {
// handle next image to detect
if (image) {
URL.revokeObjectURL(image);
setImage(null);
}
const url = URL.createObjectURL(e.target.files[0]); // create image url
inputImageRef.current.src = url; // set image source
const canvas2DCtx = canvasInputRef.current?.getContext("2d");
inputImageRef.current.onload = async () => {
if (!inputImageRef.current) return;
if (canvas2DCtx) {
canvas2DCtx.drawImage(
inputImageRef.current,
0,
0,
modelConfig.inputShape[2],
modelConfig.inputShape[3]
);
}
};
setImage(url);
}
}}
/>
</main>
);
}Reference: https://github.com/microsoft/onnxruntime-nextjs-template/blob/main/next.config.js
npm run dev
https://github.com/satyajitghana/web-yolo-onnx
NOTES:
- LLAMA2 on ONNX Runtime: https://github.com/microsoft/Llama-2-Onnx/blob/main/ChatApp/ChatApp.md
- LLM on Web: https://github.com/mlc-ai/mlc-llm
- GGML.js: https://github.com/rahuldshetty/ggml.js
- https://github.com/rahuldshetty/ggml.js-examples
- Transformer.js: https://huggingface.co/docs/transformers.js/index