Multi-Modal LLMs
GPT4V

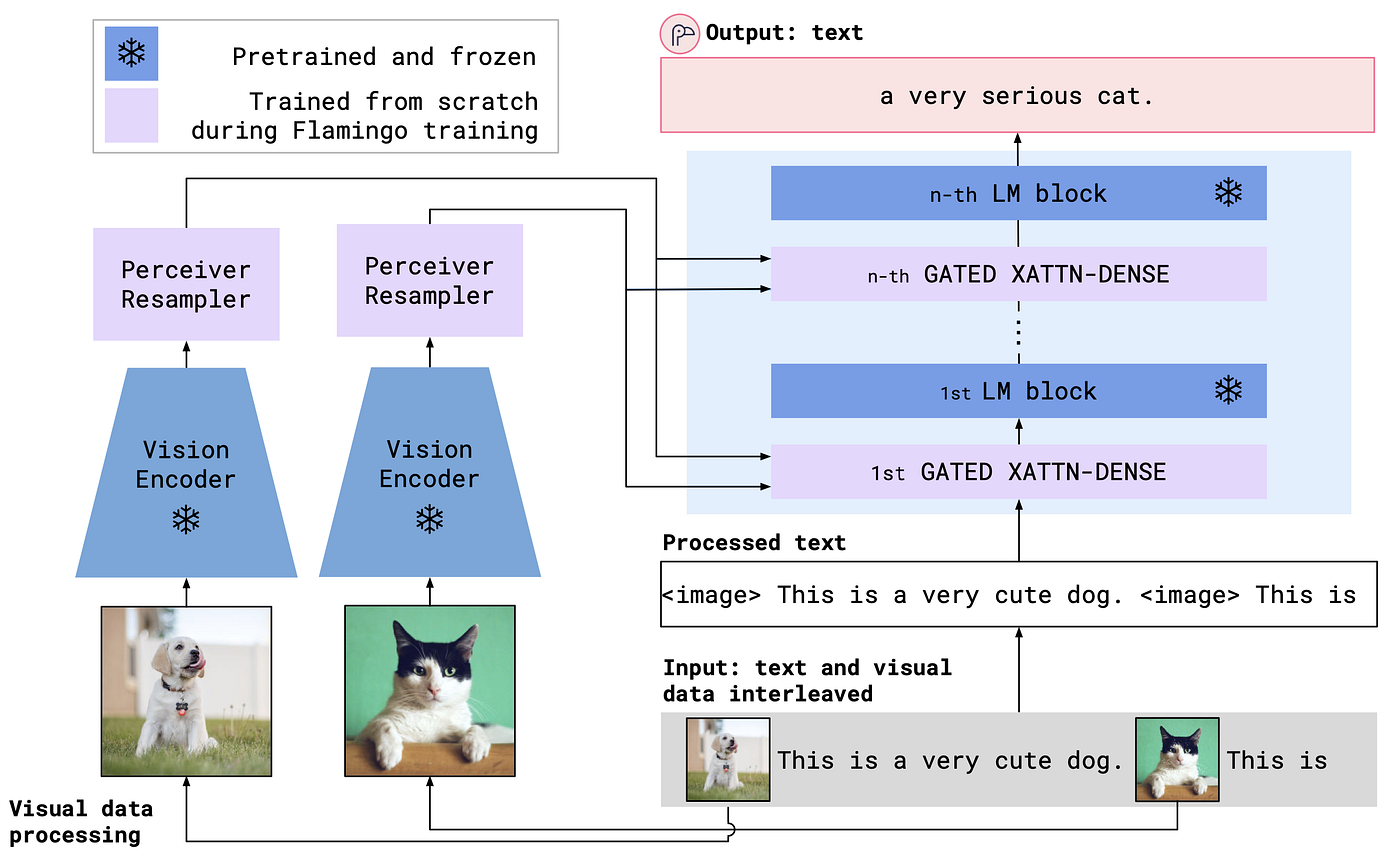
Flamingo
Flamingo is CLIP + a language model, with added techniques to make it possible for the language model to generate text tokens conditioned on both visual and text inputs.
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision): https://arxiv.org/pdf/2309.17421.pdf
GPT4V Evaluations: https://arxiv.org/pdf/2310.16534.pdf
For more on Multi Modal LLM read this: https://huyenchip.com/2023/10/10/multimodal.html
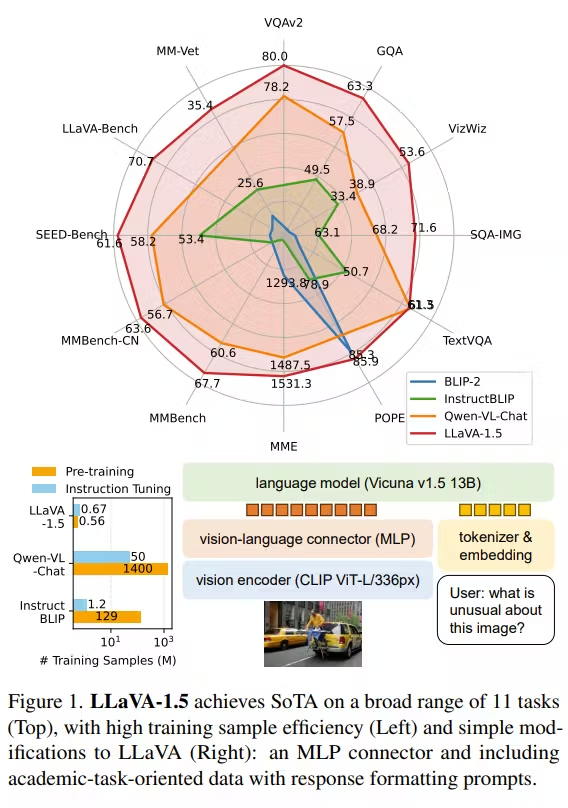
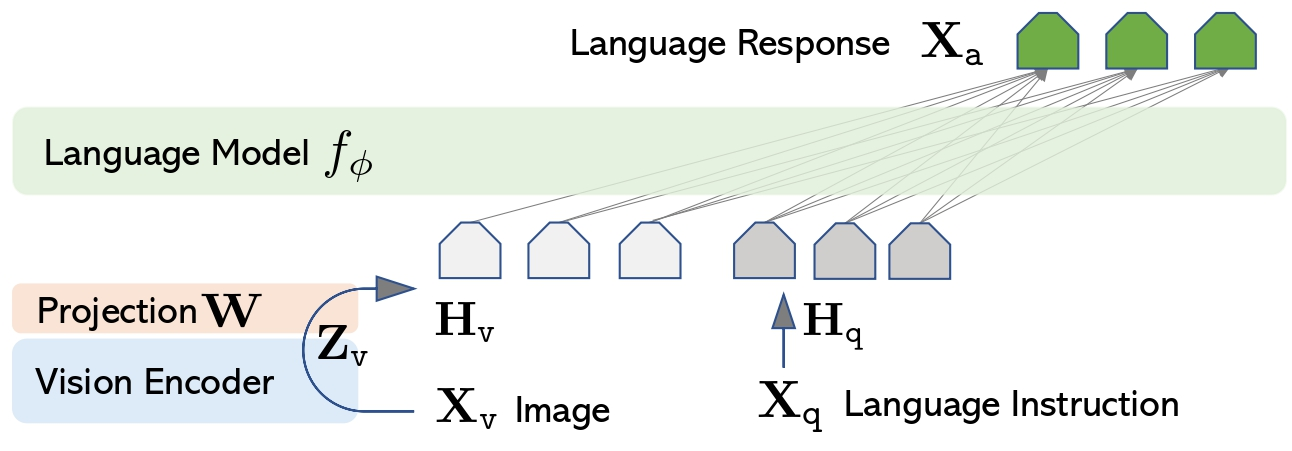
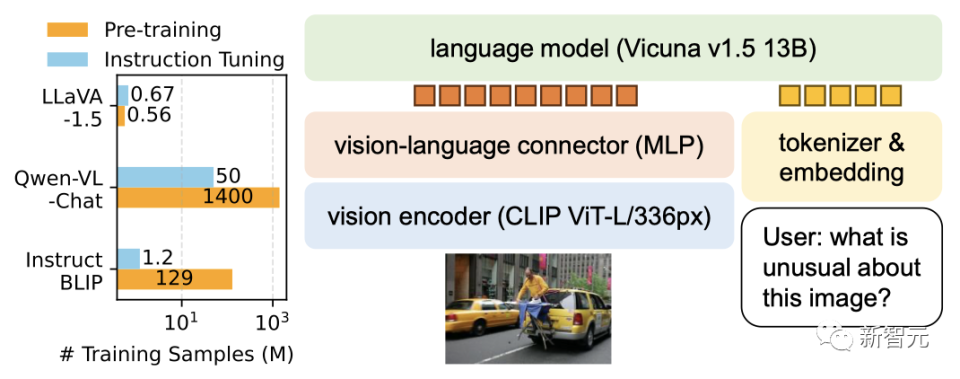
LLaVA
https://arxiv.org/abs/2304.08485

Demo: https://llava.hliu.cc/

You’ll need the latest version of transformers for any of these MM-LLM’s to run
from transformers import pipeline
from PIL import Image
import requests
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text", model=model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/ai2d-demo.jpg"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "USER: <image>\nWhat does the label 15 represent? (1) lava (2) core (3) tunnel (4) ash cloud\nASSISTANT:"
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200})
print(outputs)import requests
from PIL import Image
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration
model_id = "llava-hf/bakLlava-v1-hf"
prompt = "USER: <image>\nWhat are these?\nASSISTANT:"
image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(0)
processor = AutoProcessor.from_pretrained(model_id)
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(prompt, raw_image, return_tensors='pt').to(0, torch.float16)
output = model.generate(**inputs, max_new_tokens=200, do_sample=False)
print(processor.decode(output[0][2:], skip_special_tokens=True))BakLLaVA
https://github.com/SkunkworksAI/BakLLaVA
Llava model trained with Mistral backbone
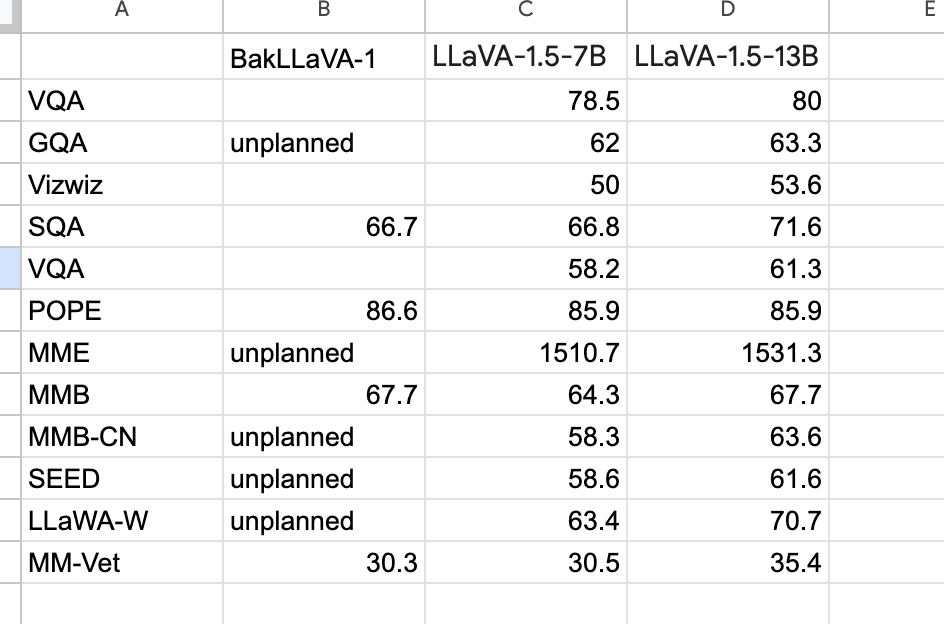
https://huggingface.co/llava-hf/bakLlava-v1-hf
! pip install --upgrade transformersfrom PIL import Image
import requests
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration, pipelinedevice = torch.device("cuda:0")
dtype = torch.bfloat16model = LlavaForConditionalGeneration.from_pretrained(
"llava-hf/bakLlava-v1-hf",
torch_dtype=dtype,
low_cpu_mem_usage=True,
device_map=device
)
processor = AutoProcessor.from_pretrained("llava-hf/bakLlava-v1-hf")image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
raw_image = Image.open(requests.get(image_file, stream=True).raw)prompt = """
USER: <image>
Describe the image
ASSISTANT:
"""inputs = processor(prompt, raw_image, return_tensors='pt').to(device, dtype)
output = model.generate(**inputs, max_new_tokens=200, do_sample=False)print(processor.decode(output[0, inputs['input_ids'].shape[1]:], skip_special_tokens=True))Multiple images
prompt = """
USER: <image>
Describe the image
ASSISTANT:
The image features two cats lying on a couch, both appearing to be quite relaxed. One cat is located towards the left side of the couch, while the other cat is situated more towards the right side. They are both close to each other, possibly enjoying each other's company.
There are two remote controls in the scene, one placed near the left cat and the other one positioned closer to the right cat. This suggests that the cats' owner might have been watching TV or using some electronic device while the cats were resting on the couch.
USER: <image>
Okay what about this image?
ASSISTANT
"""inputs = processor(prompt, [raw_image, img2], return_tensors='pt').to(device, dtype)
output = model.generate(**inputs, max_new_tokens=200, do_sample=False)CogVLM
https://github.com/THUDM/CogVLM
https://modelscope.cn/models/ZhipuAI/CogVLM/summary
Backend - Deploy BakLLaVA with FastAPI
We’re going to deploy llava-hf/bakLlava-v1-hf with OpenAI like backend spec, so we can directly use openai sdk to call our inference service
main.py
import base64
import time
from io import BytesIO
from threading import Thread
from typing import AsyncGenerator, Dict, Generator, List
import requests
import torch
import uvicorn
from fastapi import FastAPI, Request
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import StreamingResponse
from PIL import Image
from transformers import (AutoProcessor, LlavaForConditionalGeneration,
TextIteratorStreamer, pipeline)
from openai_protocol import (ChatCompletionRequest,
ChatCompletionResponseStreamChoice,
ChatCompletionStreamResponse, DeltaMessage,
random_uuid)
app = FastAPI()
# Set all CORS enabled origins
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
model_name = "llava-hf/bakLlava-v1-hf"
print(f"loading model 🧨 {model_name=} ...")
device = torch.device("cuda:0")
dtype = torch.bfloat16
model = LlavaForConditionalGeneration.from_pretrained(
model_name, torch_dtype=dtype, low_cpu_mem_usage=True, device_map=device,
)
processor = AutoProcessor.from_pretrained(model_name)
print("model loaded 🚀")
def read_image(input_string):
if input_string.startswith("http"):
# Case: URL
response = requests.get(input_string)
img = Image.open(BytesIO(response.content))
elif input_string.startswith("data:image"):
# Case: base64-encoded string
_, encoded_data = input_string.split(",", 1)
img_data = base64.b64decode(encoded_data)
img = Image.open(BytesIO(img_data))
else:
raise ValueError("Unsupported input format")
return img
@app.post("/v1/chat/completions")
async def create_chat_completion(request: ChatCompletionRequest, raw_request: Request):
request_id = f"cmpl-{random_uuid()}"
created_time = int(time.monotonic())
chunk_object_type = "chat.completion.chunk"
request.n = 1 # we will only generate 1 response choice
prompt = ""
images = []
for message in request.messages:
if message['role'] == "user":
prompt += "USER:\n"
for content in message['content']:
if content['type'] == "text":
prompt += f"{content['text']}\n"
if content['type'] == "image_url":
# read the image
url = content['image_url']['url']
image = read_image(url)
images.append(image)
prompt += f"<image>\n"
if message['role'] == "assistant":
prompt += "ASSISTANT:\n"
for content in message['content']:
if content['type'] == "text":
prompt += f"{content['text']}\n"
prompt += "ASSISTANT:\n"
# print(prompt)
inputs = processor(text=prompt, images=images if len(images) > 0 else None, return_tensors="pt")
# print(inputs)
inputs['input_ids'] = inputs['input_ids'].to(device)
inputs['attention_mask'] = inputs['attention_mask'].to(device)
if inputs['pixel_values'] is not None:
inputs['pixel_values'] = inputs['pixel_values'].to(device)
streamer = TextIteratorStreamer(
tokenizer=processor,
skip_prompt=True,
decode_kwargs={"skip_special_tokens": True},
)
generation_kwargs = dict(
inputs, max_new_tokens=512, do_sample=True, streamer=streamer
)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
def get_role() -> str:
return "assistant"
async def completion_stream_generator() -> AsyncGenerator[str, None]:
# Send first response for each request.n (index) with the role
role = get_role()
for i in range(request.n):
choice_data = ChatCompletionResponseStreamChoice(
index=i, delta=DeltaMessage(role=role), finish_reason=None
)
chunk = ChatCompletionStreamResponse(
id=request_id,
object=chunk_object_type,
created=created_time,
choices=[choice_data],
model=model_name,
)
data = chunk.model_dump_json(exclude_unset=True)
yield f"data: {data}\n\n"
# Send response for each token for each request.n (index)
previous_texts = [""] * request.n
finish_reason_sent = [False] * request.n
for res in streamer:
res: str
if finish_reason_sent[i]:
continue
# Send token-by-token response for each request.n
delta_text = res
previous_texts[i] = res
choice_data = ChatCompletionResponseStreamChoice(
index=i, delta=DeltaMessage(content=delta_text), finish_reason=None
)
chunk = ChatCompletionStreamResponse(
id=request_id,
object=chunk_object_type,
created=created_time,
choices=[choice_data],
model=model_name,
)
data = chunk.model_dump_json(exclude_unset=True)
yield f"data: {data}\n\n"
choice_data = ChatCompletionResponseStreamChoice(
index=i, delta=DeltaMessage(), finish_reason="length"
)
chunk = ChatCompletionStreamResponse(
id=request_id,
object=chunk_object_type,
created=created_time,
choices=[choice_data],
model=model_name,
)
data = chunk.model_dump_json(exclude_unset=True, exclude_none=True)
yield f"data: {data}\n\n"
finish_reason_sent[i] = True
# Send the final done message after all response.n are finished
yield "data: [DONE]\n\n"
thread.start()
return StreamingResponse(
completion_stream_generator(), media_type="text/event-stream"
)
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000, log_level="info")openai_protocol.py: https://github.com/satyajitghana/tsai-chat-vision-backend/blob/master/openai_protocol.py
Start the server!
❯ python main.py
loading model 🧨 model_name='llava-hf/bakLlava-v1-hf' ...
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████| 4/4 [00:07<00:00, 1.78s/it]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
model loaded 🚀
INFO: Started server process [1418847]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
INFO: 127.0.0.1:46598 - "POST /v1/chat/completions HTTP/1.1" 200 OK
INFO: 127.0.0.1:41152 - "POST /v1/chat/completions HTTP/1.1" 200 OKTest with openai python sdk
from openai import OpenAIopenai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)response = client.chat.completions.create(
model="llava-hf/bakLlava-v1-hf",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",
},
},
],
}
],
max_tokens=300,
stream=True
)for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")Cool!
Time for Frontend
https://github.com/satyajitghana/tsai-chat-vision
npm install
npm run devmodify config/site.ts with the backend url
We can expose the backend to internet using pinggy
ssh -p 443 -R0:localhost:8000 a.pinggy.ioHere’s how the UI looks like
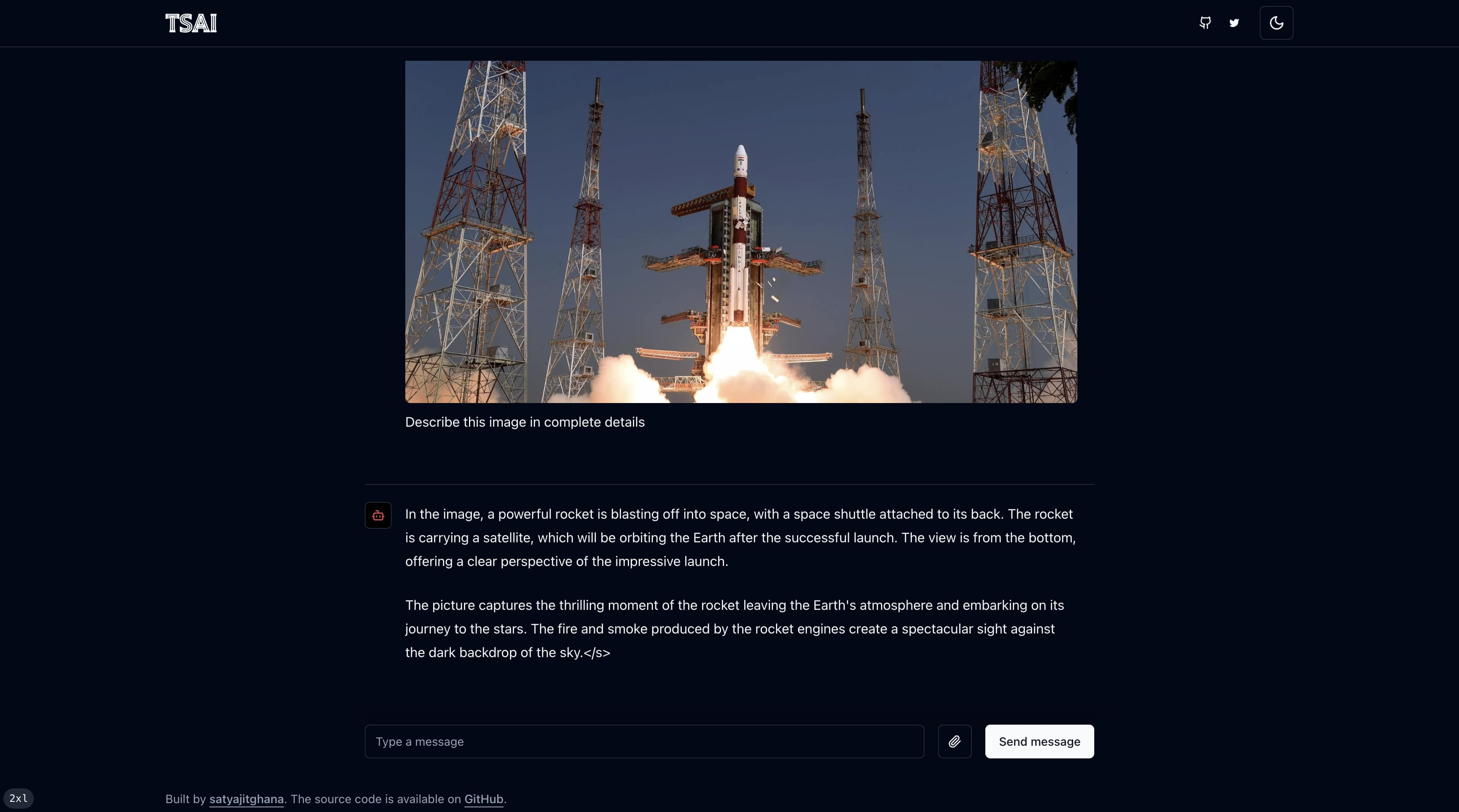
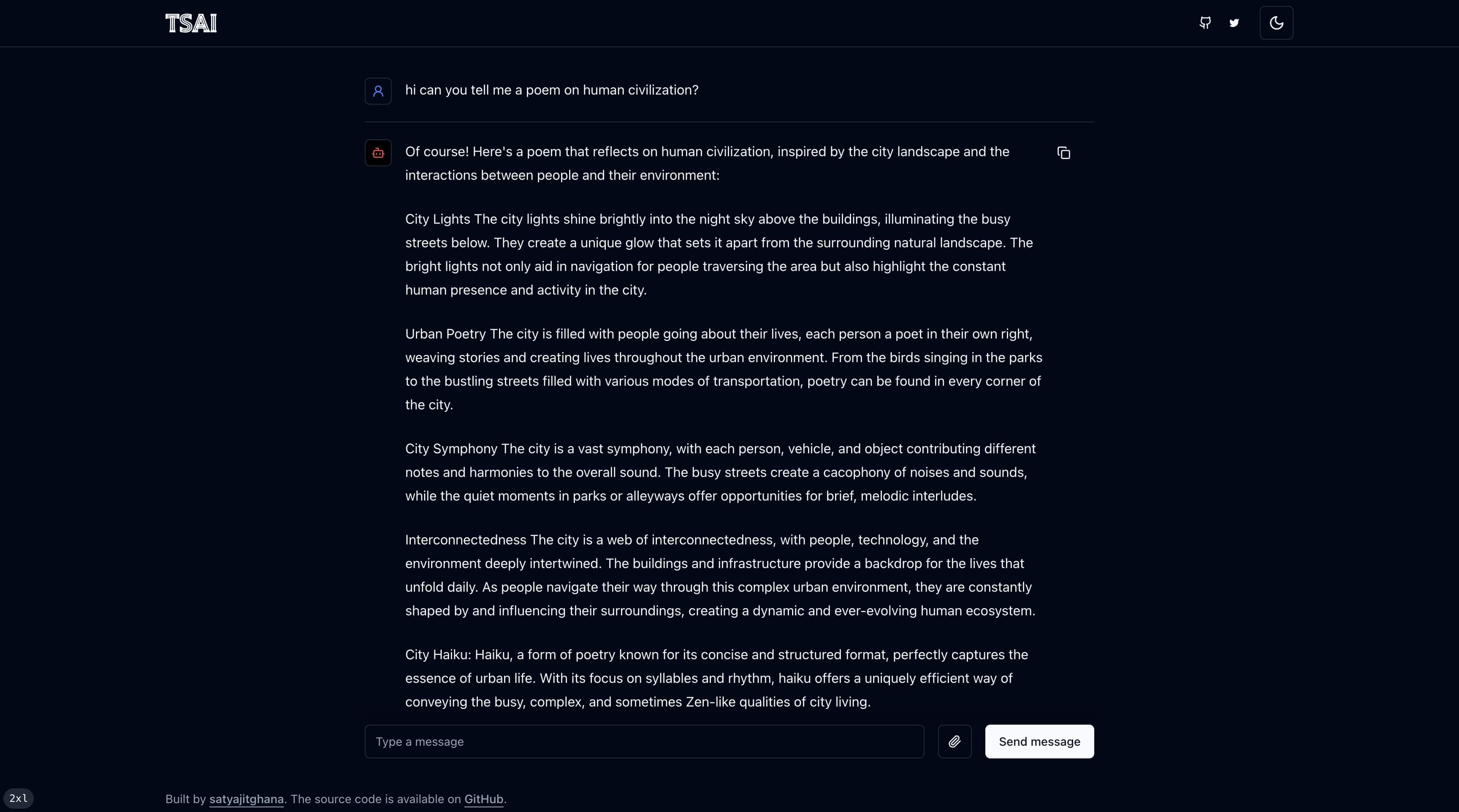
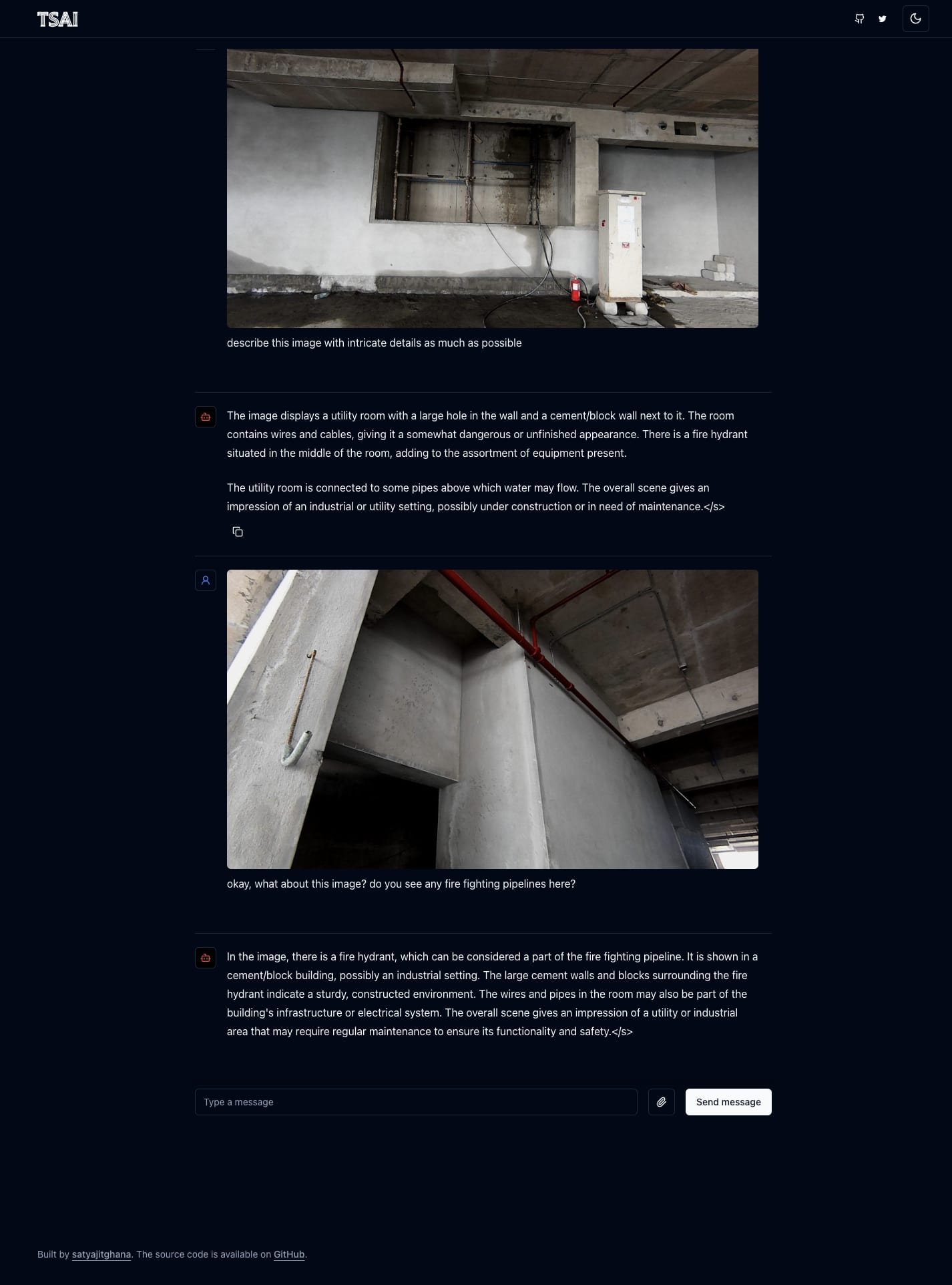
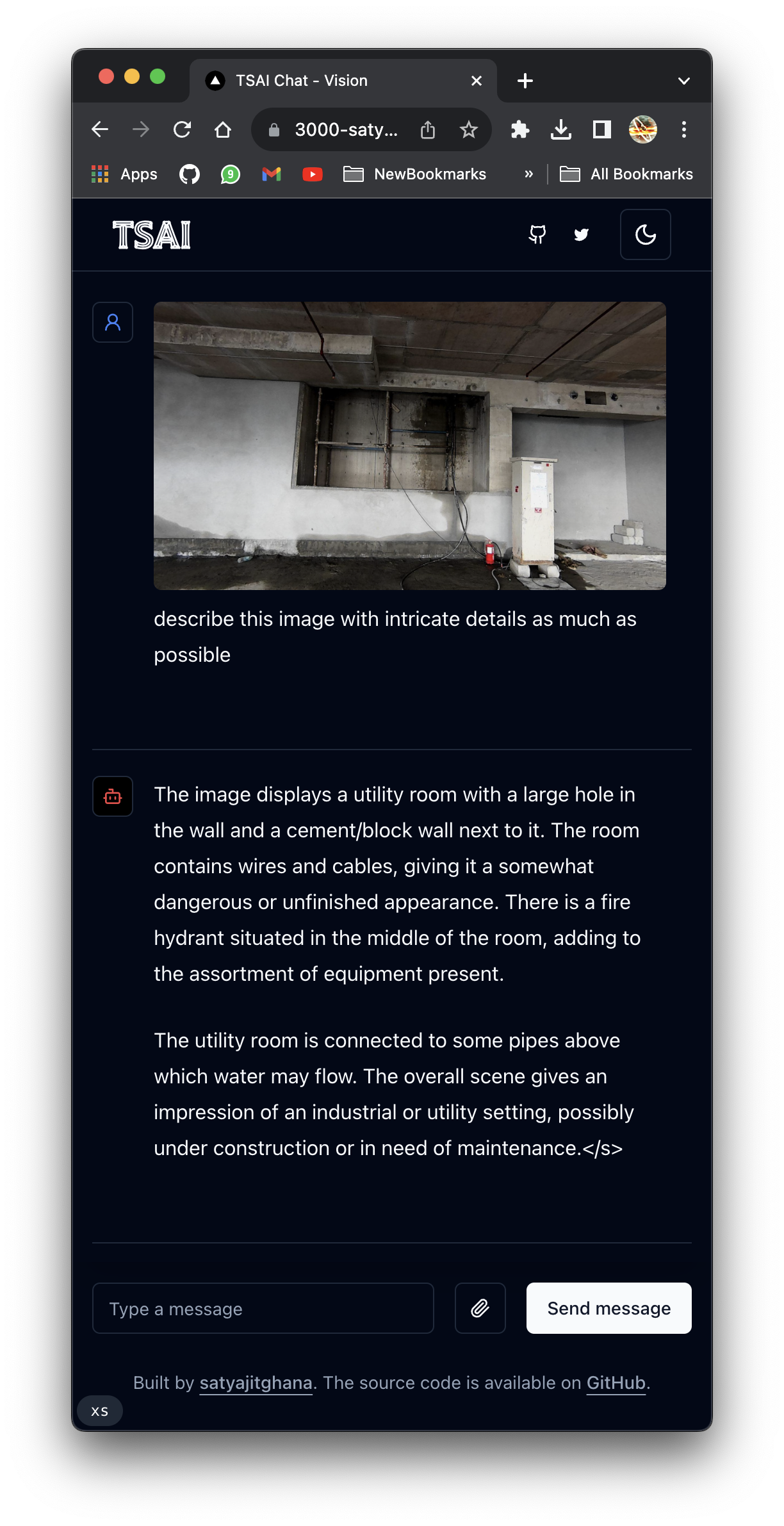
Frontend
https://github.com/satyajitghana/tsai-chat-vision
Backend
https://github.com/satyajitghana/tsai-chat-vision-backend
NOTES: