The LLM Leaderboard
| Model | Size | MMLU | Release |
|---|---|---|---|
| Gemini Ultra | 1.5T* | 90.04 *(CoT@32) | |
| 83.79 *(CoT@5) | 07-Dec-23 | ||
| Human | 86B | 89.8 | 300,000 years ago |
| GPT-4 | 1.76T* | 86.5 *(CoT@5) | |
| 87.29 *(CoT@32) | 27-Mar-23 | ||
| Gemini Pro | 180B* | 79.13 *(CoT@32) | 07-Dec-23 |
| Claude 2 | 130B | 78.5 | 11-Jul-23 |
| PaLM 2 | 340B | 78.3 | 17-May-23 |
| mistralai/Mixtral-8x7B-v0.1 | 50B | 71.73 | 10-Dec-23 |
| tiiuae/falcon-180B | 180B | 70.5 | 06-Sep-23 |
| GPT-3.5 | 175B* | 70.0 | 15-Mar-22 |
| meta-llama/Llama-2-70b-hf | 70B | 69.83 | 18-Jul-23 |
| TigerResearch/tigerbot-70b-chat-v4-4k | 70B | 68.26 | 17-Nov-23 |
| Qwen/Qwen-72B | 72B | 77.37 | 26-Nov-23 |
| kyujinpy/PlatYi-34B-LoRA | 34B | 78.46 | 01-Dec-23 |
| SUSTech/SUS-Chat-34B | 34B | 76.41 | 29-Nov-23 |
| OrionStarAI/OrionStar-Yi-34B-Chat-Llama | 34B | 73.67 | 21-Nov-23 |
| deepseek-ai/deepseek-llm-67b-chat | 67B | 72.42 | 29-Nov-23 |
| Qwen/Qwen-14B | 14B | 67.7 | 24-Sep-23 |
| openchat/openchat_3.5 | 7B | 64.98 | 30-Oct-23 |
| 01-ai/Yi-6B-200K | 6B | 64.65 | 06-Nov-23 |
| mistralai/Mistral-7B-v0.1 | 7B | 64.16 | 20-Sep-23 |
| Intel/neural-chat-7b-v3-2 | 7B | 63.55 | 21-Nov-23 |
| fblgit/una-cybertron-7b-v2-bf16 | 7B | 63.23 | 02-Dec-23 |
| meta-llama/Llama-2-13b-hf | 13B | 55.77 | 18-Jul-23 |
| GeneZC/MiniChat-1.5-3B | 3B | 46.67 | 26-Nov-23 |
| bigscience/bloomz-3b | 3B | 32.91 | 02-Oct-22 |
| MBZUAI/LaMini-GPT-1.5B | 1.5B | 29.92 | 16-Apr-23 |
| deepseek-ai/deepseek-coder-1.3b-instruct | 1.3B | 28.47 | 29-Oct-23 |
| postbot/emailgen-pythia-410m-deduped | 510M | 27.35 | 15-Feb-23 |
| nicholasKluge/Aira-2-355M | 355M | 27.26 | 08-Jun-23 |
| bigcode/tiny_starcoder_py | 164M | 26.79 | 15-May-23 |
| MBZUAI/LaMini-Neo-125M | 125M | 26.74 | 14-Apr-23 |
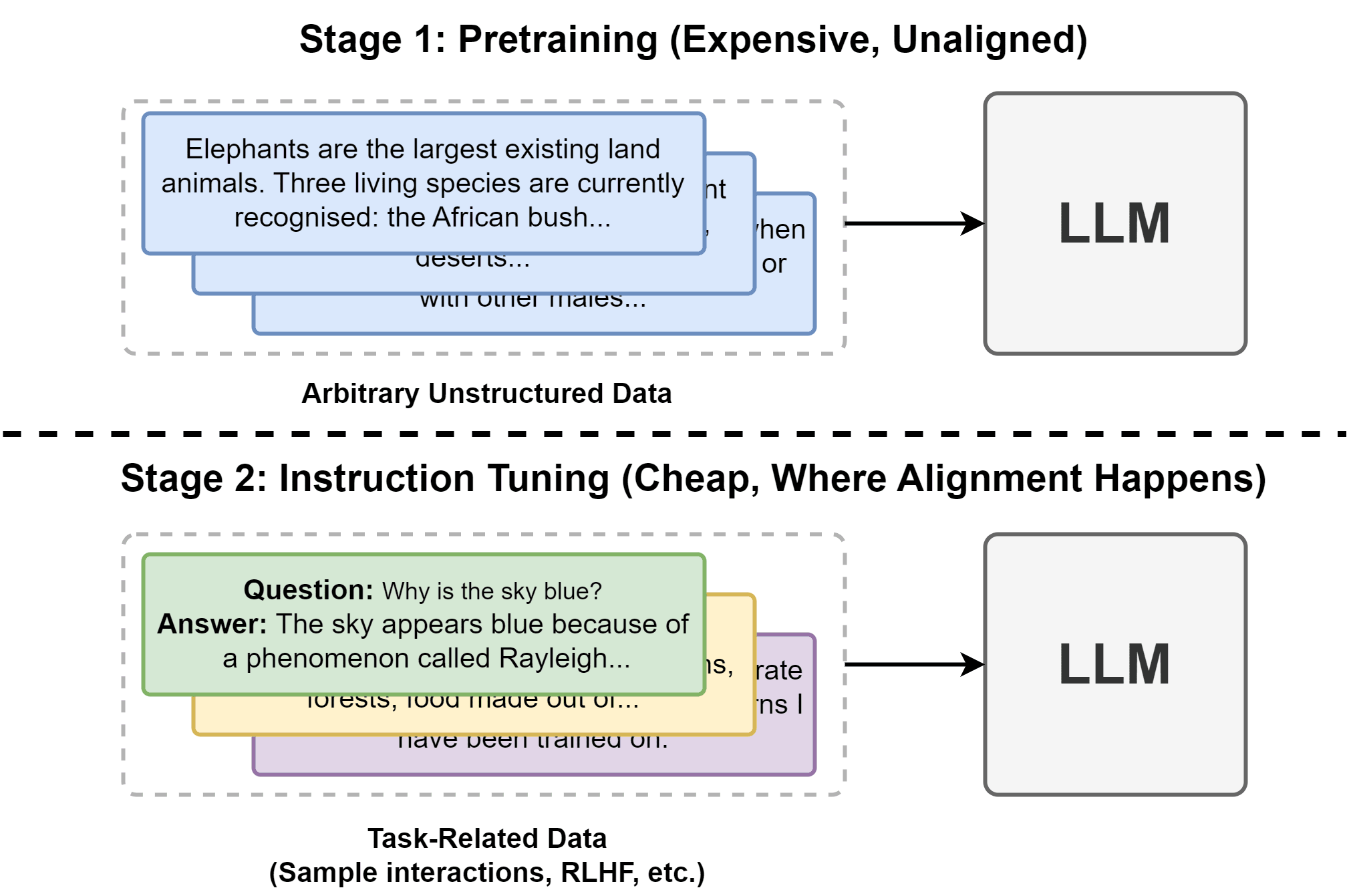
Pre-Training
A language model captures statistical patterns in language, indicating the likelihood of specific elements (such as words or characters) appearing in a particular context. The term "token" encompasses words, characters, or word components (like -tion), depending on the language model, essentially representing the model's vocabulary.
Individuals proficient in a language possess subconscious statistical knowledge of it. For instance, consider the context "In my spare time, I enjoy __," where English speakers would anticipate that the missing word is more likely to be a recreational activity (e.g., reading) than an object (e.g., chair).
Likewise, language models should excel at completing such prompts. Picture a language model as a "completion engine": when presented with a text (prompt), it can generate a response to seamlessly finish that text. As an illustration:
User's Prompt: "After a challenging day at work, I like to unwind by __." Language Model's Completion: "After a challenging day at work, I like to unwind by taking a leisurely stroll in the park."
Objective:
The goal of pre-training is to initialize the language model using a large corpus of unlabeled data.
Pre-training typically involves the use of a language modeling objective, such as masked language modeling or predicting the next word (or sentence) in a sequence.
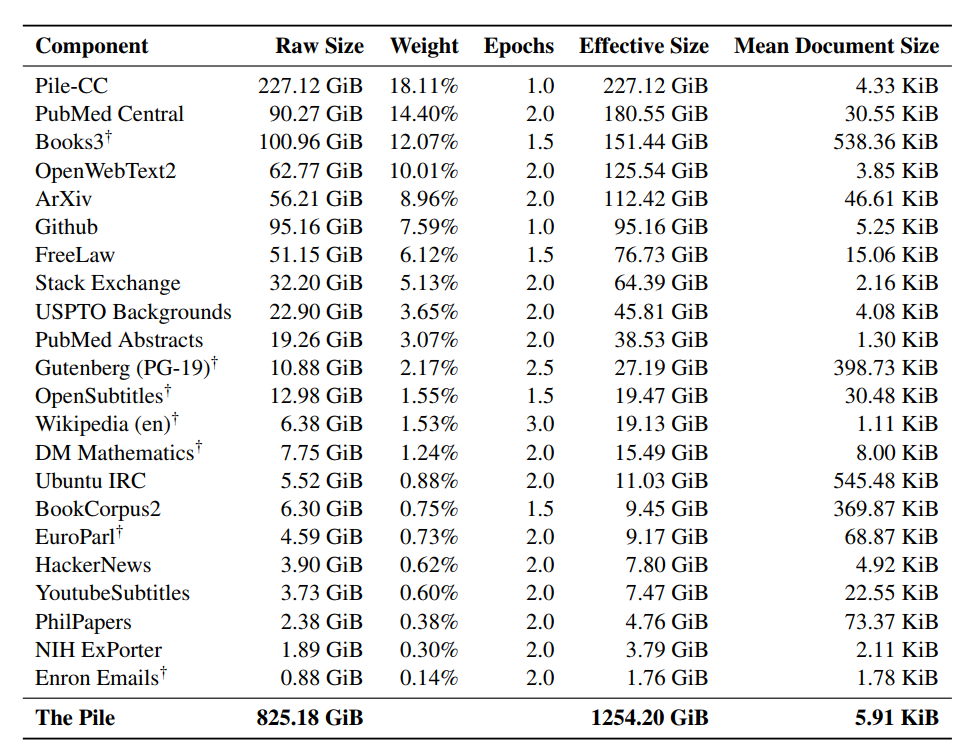
- Training data: low-quality data
- Data scale: usually in the order of trillions of tokens as of May 2023.
- GPT-3’s dataset (OpenAI): 0.5 trillion tokens. I can’t find any public info for GPT-4, but I’d estimate it to use an order of magnitude more data than GPT-3.
- Gopher’s dataset (DeepMind): 1 trillion tokens
- RedPajama (Together): 1.2 trillion tokens
- LLaMa’s dataset (Meta): 1.4 trillion tokens
Example:
Consider using a pre-trained LM like GPT-3.5 on a diverse dataset like the OpenWebText dataset. The model is trained to predict the next word in a given sentence based on the context provided by the preceding words.
As language models replicate the patterns within their training data, their effectiveness is contingent upon the quality of that data, giving rise to the adage "Garbage in, garbage out." Should you choose to train a language model using Reddit comments, presenting it to your parents might not be the wisest decision.
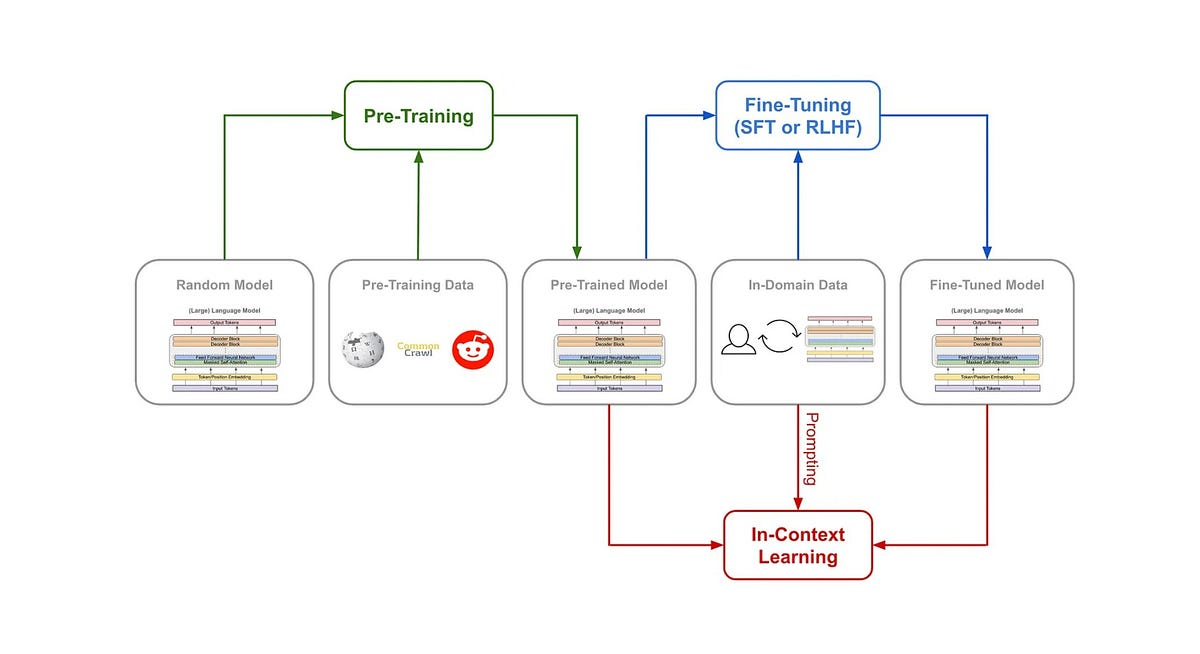
After pre-training, the model learns a rich representation of language and acquires knowledge about various linguistic aspects.
However, this pre-trained model still needs to be tweaked to perform specific tasks effectively.
That’s where the fine-tuning comes
Supervised Fine-Tuning
Pretraining focuses on refining the language model's ability to complete tasks. When presented with a question in its pretrained state, such as "How to make pizza," various responses could be considered valid. These may include adding more context to the question, like "for a family of six," introducing follow-up questions such as "What ingredients do I need? How much time would it take?" or directly providing the answer. Opting for the third option is preferable when seeking a direct response. The objective of Supervised Finetuning (SFT) is to fine-tune the pretrained model to generate responses aligned with user expectations.
Objective:
Fine-tuning is performed on a domain-specific dataset to adapt the pre-trained LM to a particular task or dataset. This process helps the model generate more relevant and accurate responses for a specific application.
- Training data: high-quality data in the format of (prompt, response)
- Data scale: 10,000 - 100,000 (prompt, response) pairs
- InstructGPT: ~14,500 pairs (13,000 from labelers + 1,500 from customers)
- Alpaca: 52K ChatGPT instructions
- Databricks’ Dolly-15k: ~15k pairs, created by Databricks employees
- OpenAssistant: 161,000 messages in 10,000 conversations -> approximately 88,000 pairs
- Dialogue-finetuned Gopher: ~5 billion tokens, which I estimate to be in the order of 10M messages. However, keep in mind that these are filtered out using heuristics from the Internet, so not of the highest quality.
- Model input and output
- Input: prompt
- Output: response for this prompt
Example:
Fine-tune the pre-trained LM on the Alpaca dataset to generate responses that are contextually relevant to topics related to alpacas.
RLHF
Imagine this idea: What if we had a way to measure how good a response is to a given prompt? Well, we could create a scoring function for that. This function would take a prompt and a response and tell us how good the response is. Then, we could use this scoring function to teach our language models to give better responses.
That's where Reinforcement Learning from Human Feedback (RLHF) comes in. RLHF has two main parts:
- Training a Reward Model: We create a reward model, which is like our scoring function. This model learns to evaluate and score responses based on how good they are.
- Optimizing the Language Model: We then train our language model to generate responses that get high scores from the reward model. In other words, the language model learns to improve and give better answers according to the scoring function we've set up.
Objective:
RLHF is an iterative process that refines the fine-tuned model using reinforcement learning. It involves collecting human feedback on model-generated responses and using this feedback to further improve the model.
Steps:
- Interactive Input: Collect user interactions with the model, including corrections or rankings of different responses.
- Reward Model: Use this human feedback to create a reward model that guides the model towards generating better responses.
- Fine-tuning with Proximal Policy Optimization (PPO): Apply PPO or a similar reinforcement learning algorithm to update the model's parameters based on the reward model.
Example:
This involves creating a reward model based on human feedback and updating the model using reinforcement learning algorithms like Proximal Policy Optimization (PPO).
# RLHF using custom RL algorithms
# Collect conversations and human feedback
conversations, rewards = collect_human_feedback()
# Update the model using RL algorithms (e.g., PPO)
for epoch in range(num_epochs):
for conversation, reward in zip(conversations, rewards):
updated_model = rlhf_update(model, conversation, reward)
model = updated_model
# Save the updated model
model.save('rlhf_finetuned_model')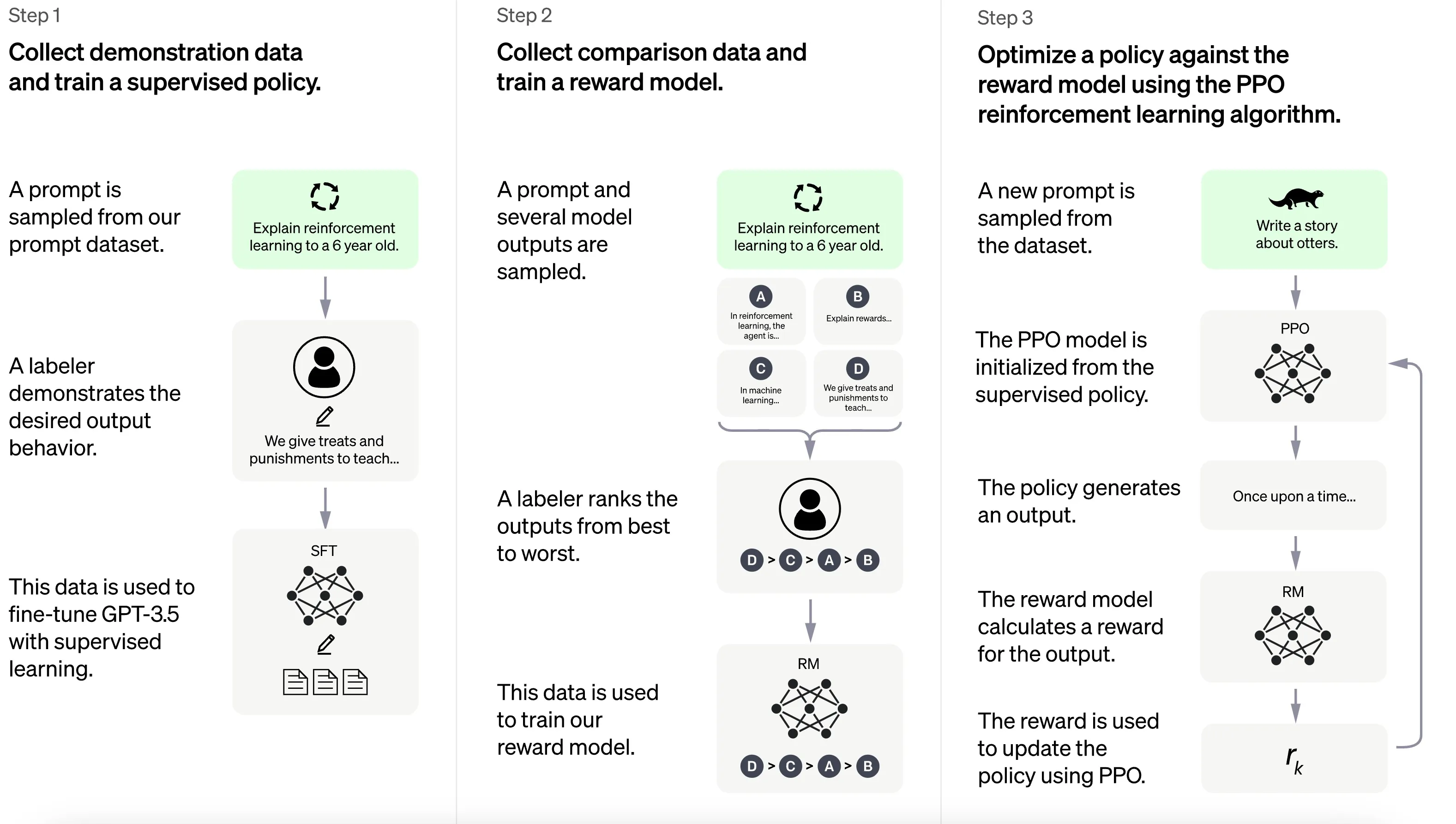
But why do we need RLHF?
Improve Model Behavior:
- Addressing Biases: RLHF allows you to correct biases or undesired behavior in the model. By collecting human feedback, you can guide the model towards generating more appropriate and unbiased responses.
Handling Ambiguity:
- Ambiguous Situations: Language is often ambiguous, and models may struggle in situations with multiple valid responses. RLHF helps the model learn from human preferences, making it more likely to generate responses that align with human expectations.
Reducing Undesirable Outputs:
- Mitigating Risks: RLHF is a tool to mitigate the risk of the model generating harmful or inappropriate content. By actively involving humans in the feedback loop, you can catch and correct undesirable outputs.
Exploration and Exploitation:
- Balancing Trade-offs: RLHF helps strike a balance between exploration and exploitation. It allows the model to explore new possibilities based on human feedback while still leveraging the knowledge gained during the initial pre-training and fine-tuning phases.
For example, if you asked a chatbot what the weather is like outside, it might respond, “It’s 30 degrees Celsius with clouds and high humidity,” or it might respond, “The temperature is around 30 degrees at the moment. It’s cloudy out and humid, so the air might seem thicker!” Although both responses say the same thing, the second response sounds more natural and provides more context.
As human users rate which model responses they prefer, you can use RLHF for collecting human feedback and improving your model to best serve real people.
Anthropic RLHF Dataset: https://huggingface.co/datasets/Anthropic/hh-rlhf
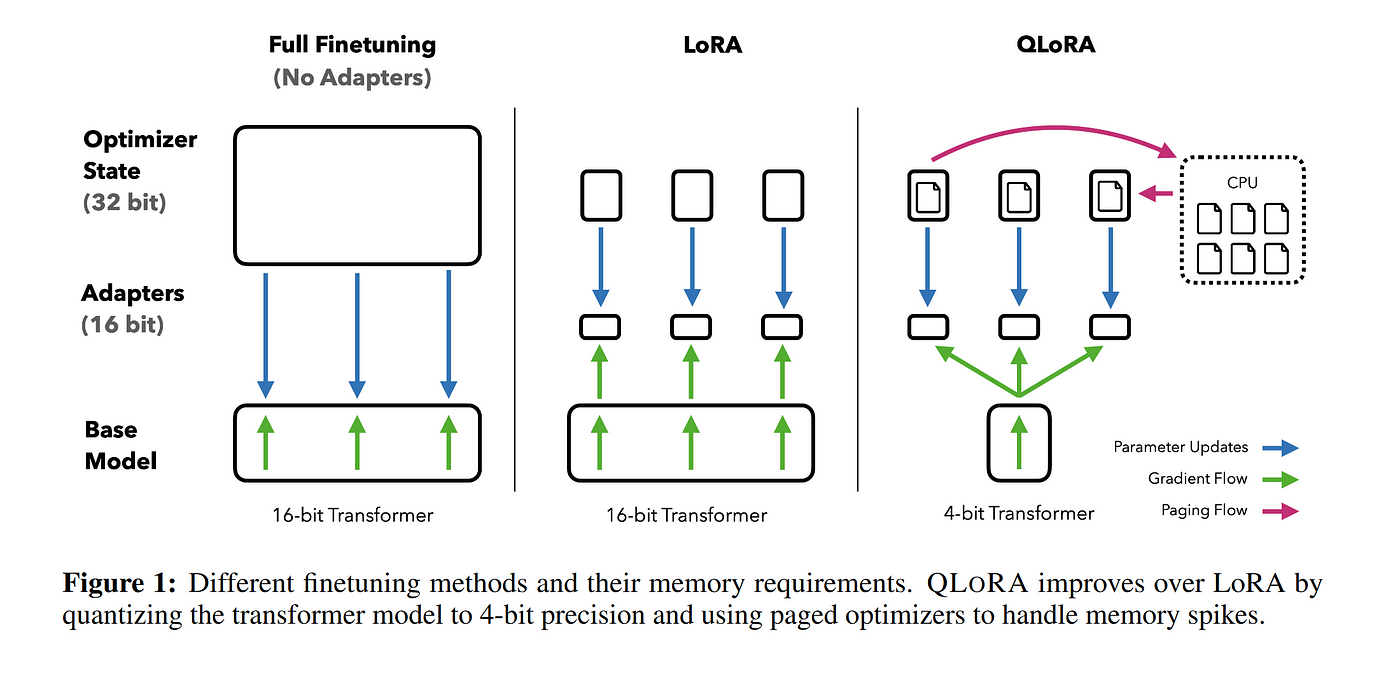
Will it Fit? Revisiting Memory Requirements

Training Compute-Optimal Large Language Models
https://arxiv.org/pdf/2203.15556.pdf
The basic equation giving the cost to train a transformer model is given by:
Where
C = Compute required to train the transformer model (FLOPS)
Here C refers to C forward + C backward
C forward = 2PD
C backward = 4PD
tau = Total FLOPS of your training infrastructure
T = Time spent in training in seconds
P = Total parameters in your model
D = Total tokens in your dataset
Cool that’s about the FLOPs required to train a model
Coming to Memory Costs
- Inference Memory
INT8 = 1 byte/param * total params
FP16 or BF16 = 2 byte/param * total params
FP32 = 4 byte/param * total params
In practice you’ll see additional overhead of 10-20%, more about it here: https://kipp.ly/transformer-inference-arithmetic/
Inference Memory = 1.2 * Model Memory
- Training Memory
Training always required more memory, why? Well, the components on GPU memory are the following: 1. model parameters 2. optimizer states 3. gradients 4. forward activations saved for gradient computation
Model Parameters
You can train your model with either FP32 or FP16 of the Model Parameters
FP32 Train = 4 bytes/param * total params
FP16 Train = 2 byte/param * total params
Optimizer States
- AdamW
- Momentum: 4 bytes/param
- Variance: 4 bytes/param
So that becomes 8 bytes/param, that’s quite inefficient?
- bitsandbytes 8-bit Adam
- Momentum: 1 byte/param
- Variance: 1 byte/param
that becomes 2 bytes/param
- SGD
- Momentum: 4 bytes/param
that becomes 4 bytes/param
Gradients
FP32 Gradients = 4 byte/param * total params
FP16 Gradients = 4 byte/param * total params
Activations
size depends on many factors, the key ones being sequence length, hidden size and batch size.
There are the input and output that are being passed and returned by the forward and the backward functions and the forward activations saved for gradient computation.
As per the paper,
Reducing Activation Recomputation in Large Transformer Models
https://arxiv.org/pdf/2205.05198.pdf

s = sequence length in tokens
b = batch size
h = hidden dim
L = number of layers
a = number of attention heads
128 _ 4 _ 2048 * 16 (34 + 5*8*128/2048) = 592MB
Model Memory Experiments: https://colab.research.google.com/drive/1jFFBqgGu4Fs9vIjjcHcuvXKd52cIN7uM?usp=sharing
Available Optimizers in Huggingface Transformer: https://github.com/huggingface/transformers/blob/main/src/transformers/training_args.py#L133
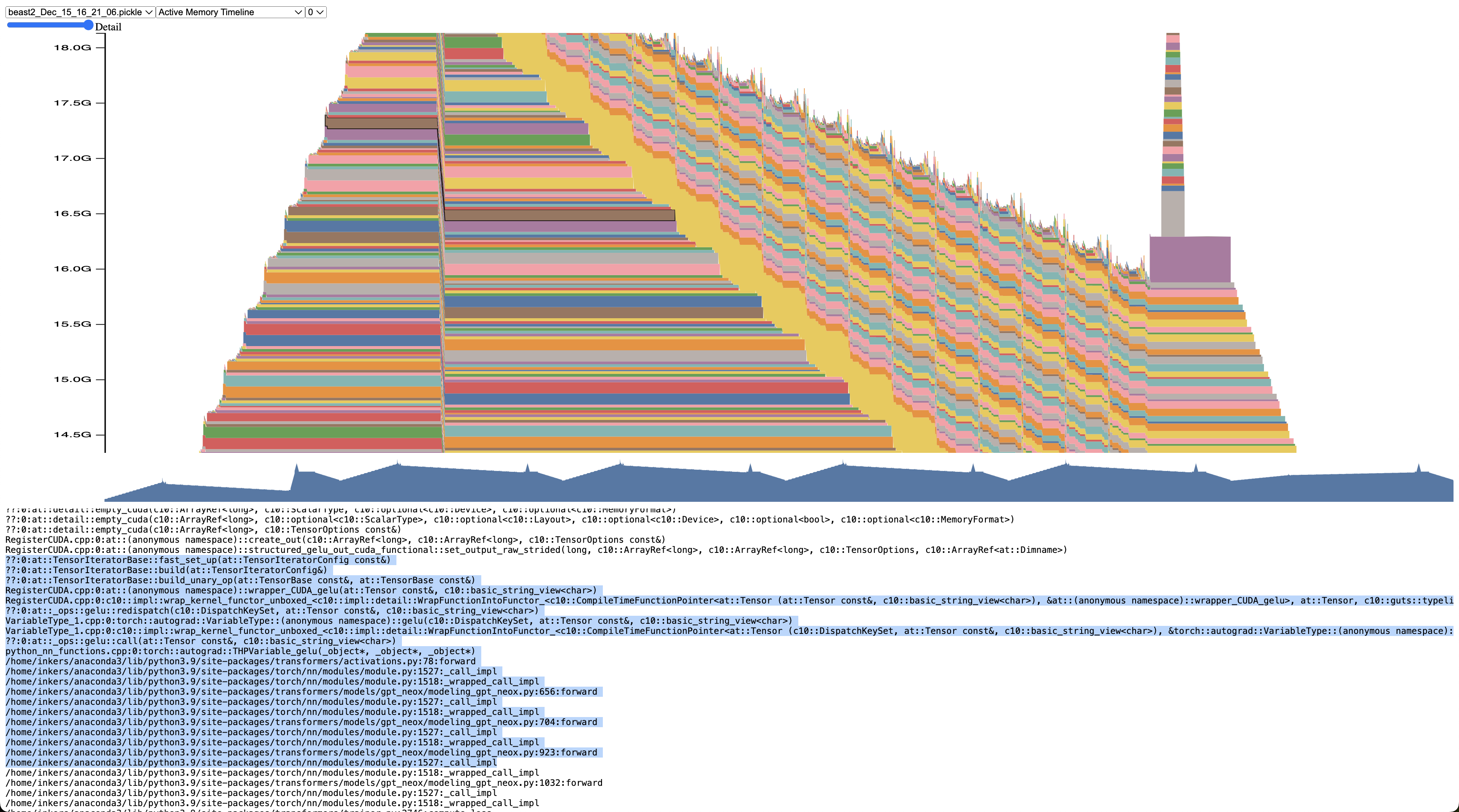
Memory Profiling & Snapshots
https://colab.research.google.com/drive/1jAndaNPhALowVwH1o1GowT6-Mm4carGV?usp=sharing
Visualize at https://pytorch.org/memory_viz
FP32, no gradient checkpointing, AdamW normal, batch size 24
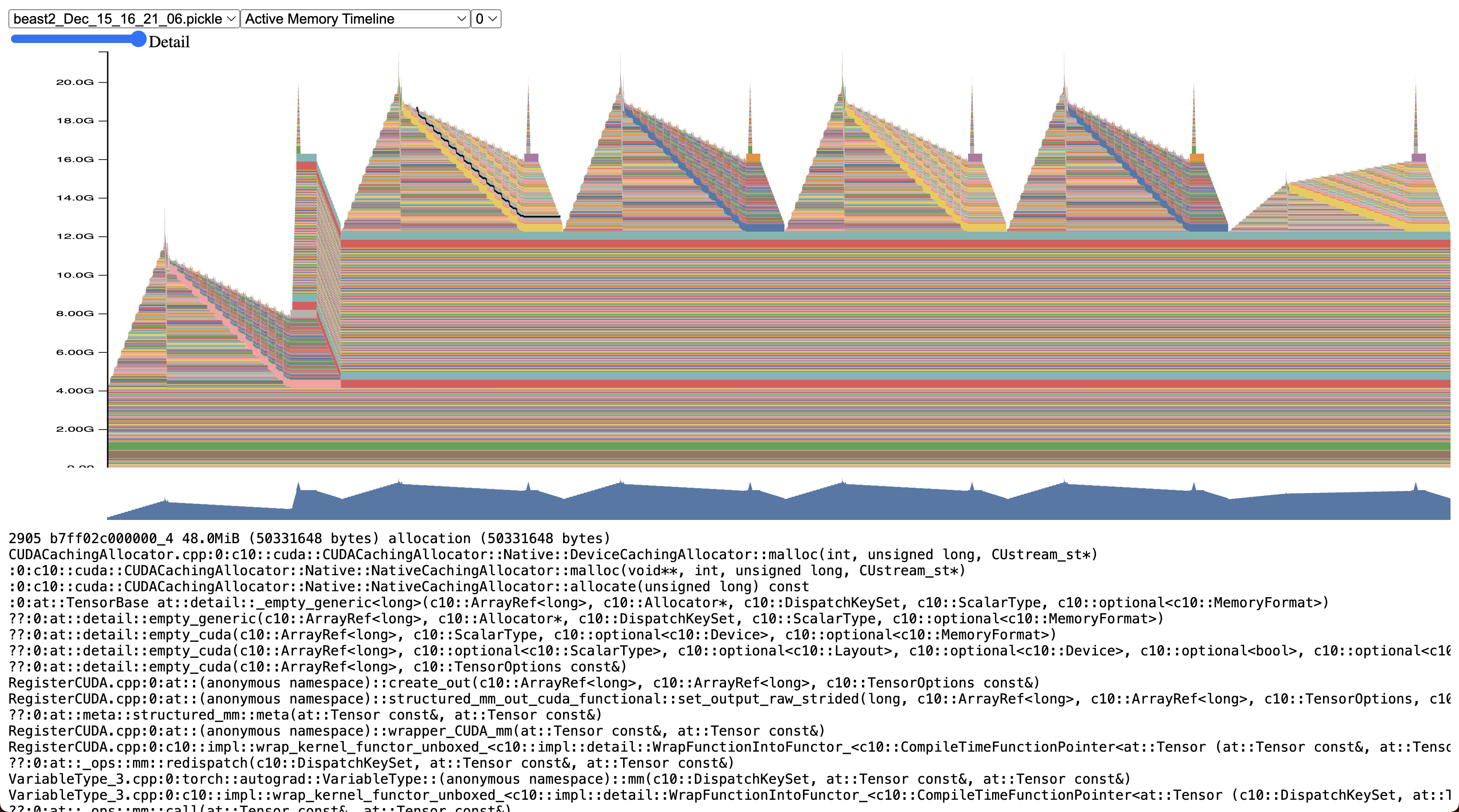
Memory Snapshot

These are the Gradients
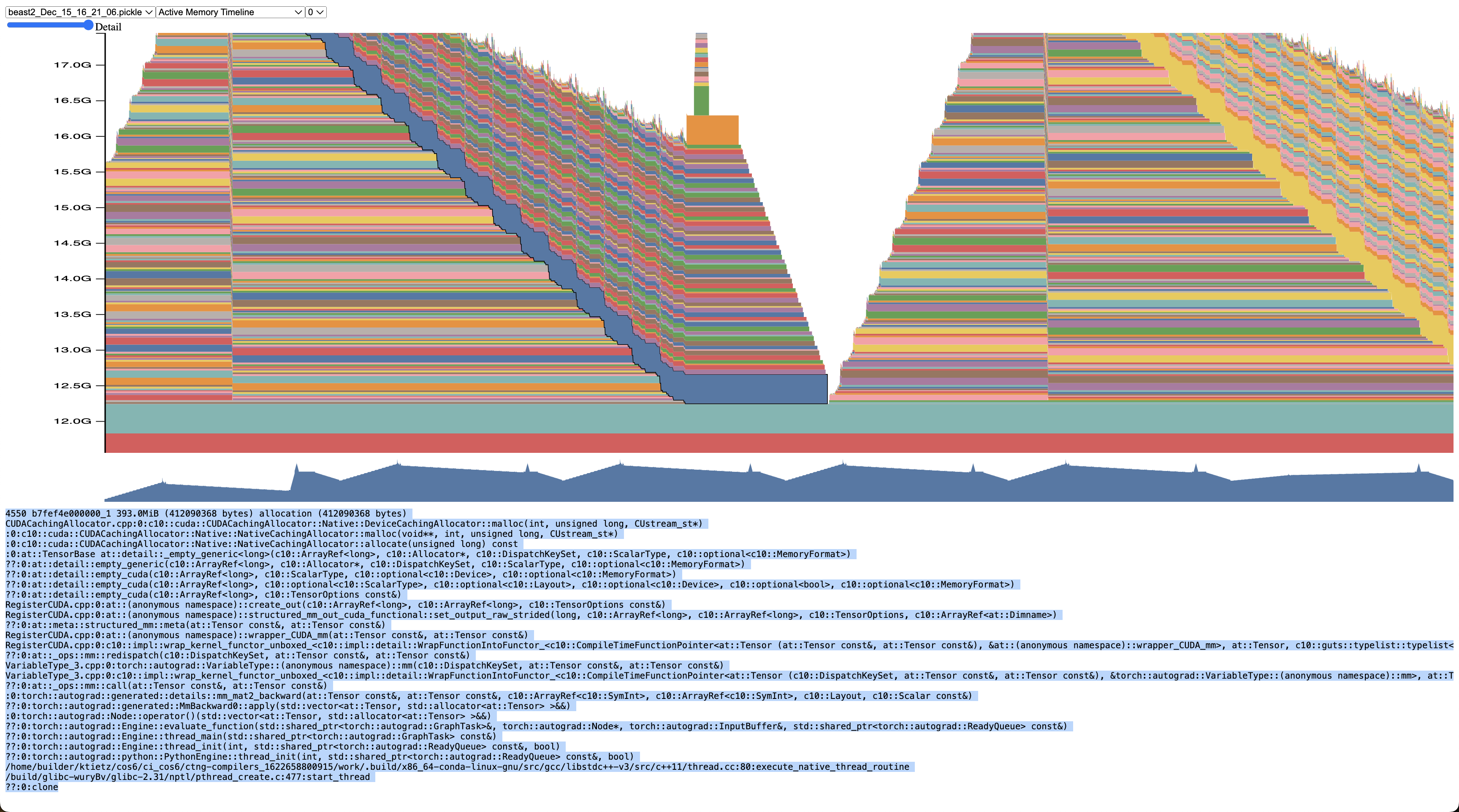
These are the forward calls (activations)
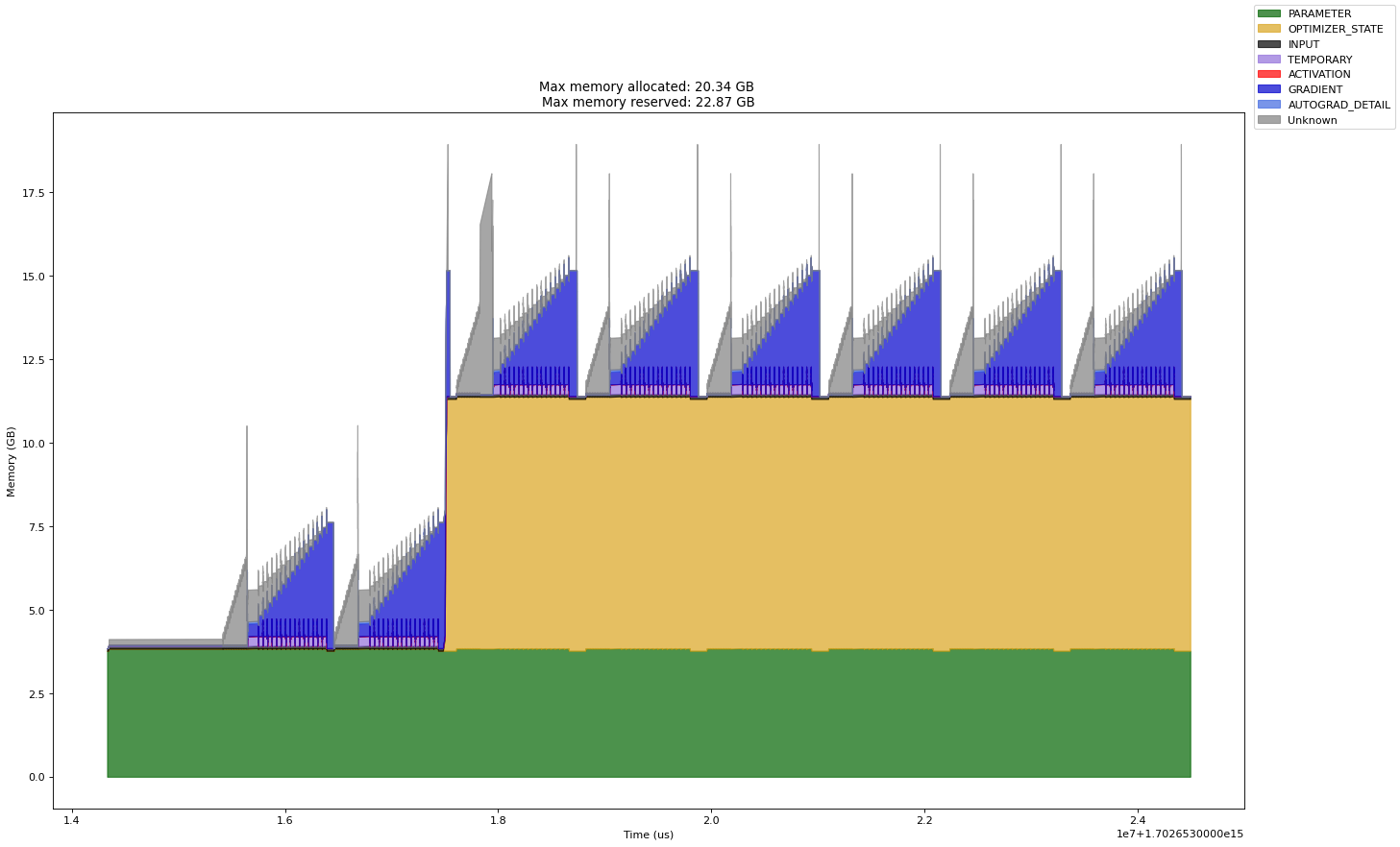
FP16, Gradient Checkpointing, Batch Size 64, AdamW
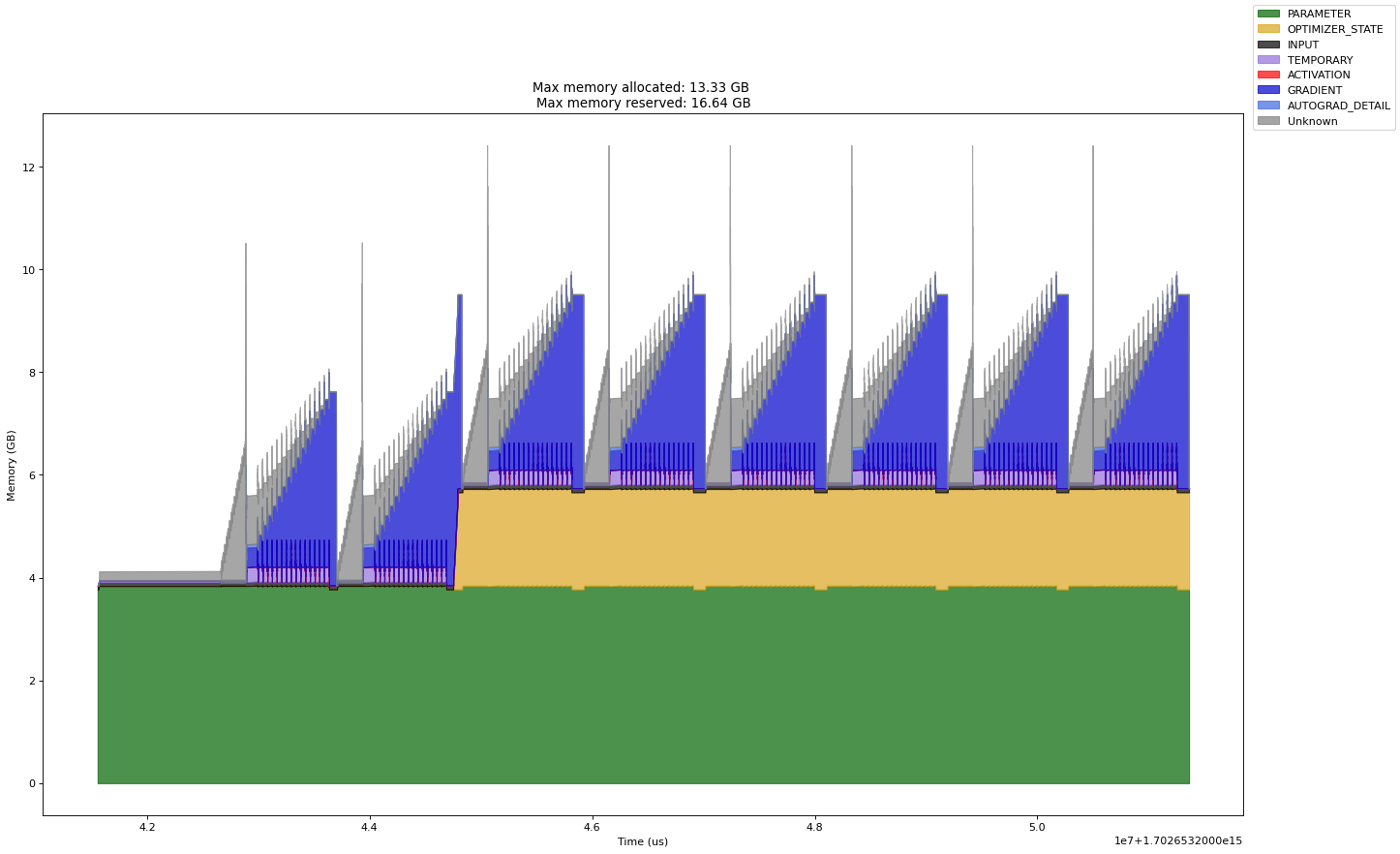
FP16, Gradient Checkpointing, Batch Size 64, 8 Bit Adam
Notice how small the optimizer memory is!
python torch/cuda/_memory_viz.py trace_plot snapshot.pickle -o snapshot.htmlAre you GPU Poor?
https://rahulschand.github.io/gpu_poor/
But mostly i found above to be inaccurate in terms of activations memory
Dataset for Fine Tuning
https://huggingface.co/datasets/argilla/databricks-dolly-15k-curated-en
https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k
https://huggingface.co/datasets/Fredithefish/openassistant-guanaco-unfiltered
https://huggingface.co/datasets/tatsu-lab/alpaca
https://huggingface.co/datasets/Open-Orca/OpenOrca
We’re going to tune our model on Alpaca GPT4 Instruction Dataset
https://huggingface.co/datasets/c-s-ale/alpaca-gpt4-data
The Alpaca Dataset Format
### Instruction:
Use the Input below to create an instruction, which could have been used to generate the input using an LLM.
### Input:
Dear [boss name],
I'm writing to request next week, August 1st through August 4th,
off as paid time off.
I have some personal matters to attend to that week that require
me to be out of the office. I wanted to give you as much advance
notice as possible so you can plan accordingly while I am away.
Please let me know if you need any additional information from me
or have any concerns with me taking next week off. I appreciate you
considering this request.
Thank you, [Your name]
### Response:
Write an email to my boss that I need next week 08/01 - 08/04 off.Model
We’re going to be tuning the Mistral 7B Model
https://huggingface.co/mistralai/Mistral-7B-v0.1
Mistral-7B-v0.1 is a transformer model, with the following architecture choices:
- Grouped-Query Attention
- Sliding-Window Attention
- Byte-fallback BPE tokenizer

Code!

This little gem of the Hugging Face ecosystem is packed with valuable tools. Most of what is relevant to instruction finetuning is in the form of preprocessing and dataset creation tools. For instance, the packing and instruction masking is built into their special Dataset classes.
SFTTrainer
https://huggingface.co/docs/trl/sft_trainer
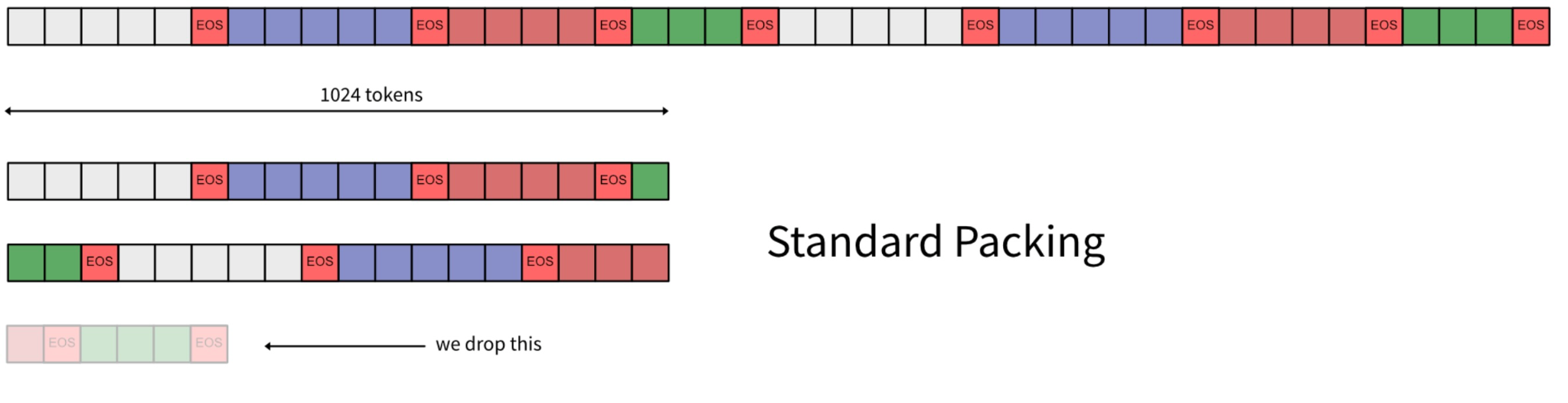
NEFTune
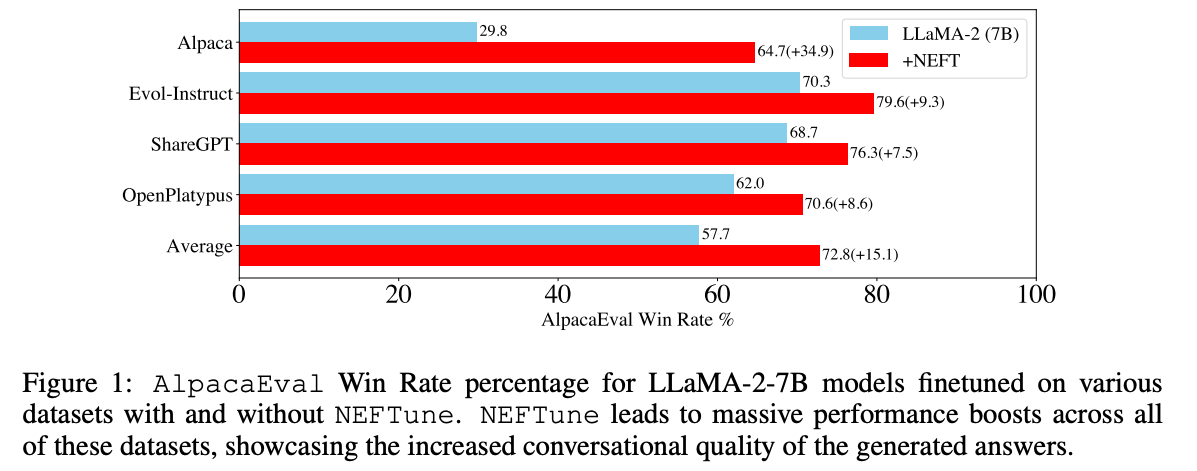
NEFTune is a technique to boost the performance of chat models and was introduced by the paper “NEFTune: Noisy Embeddings Improve Instruction Finetuning” from Jain et al. it consists of adding noise to the embedding vectors during training.
! pip install transformers datasets peft bitsandbytes accelerate trl tensorboard tensorboardX! pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.3.6/flash_attn-2.3.6+cu122torch2.1cxx11abiFALSE-cp39-cp39-linux_x86_64.whlExample of Dataset
from datasets import load_datasetalpaca_dataset = load_dataset("c-s-ale/alpaca-gpt4-data", split="train")
print(f"dataset size: {len(alpaca_dataset)}")alpaca_dataset[0]{'instruction': 'Give three tips for staying healthy.',
'input': '',
'output': '1. Eat a balanced and nutritious diet: Make sure your meals are inclusive of a variety of fruits and vegetables, lean protein, whole grains, and healthy fats. This helps to provide your body with the essential nutrients to function at its best and can help prevent chronic diseases.\n\n2. Engage in regular physical activity: Exercise is crucial for maintaining strong bones, muscles, and cardiovascular health. Aim for at least 150 minutes of moderate aerobic exercise or 75 minutes of vigorous exercise each week.\n\n3. Get enough sleep: Getting enough quality sleep is crucial for physical and mental well-being. It helps to regulate mood, improve cognitive function, and supports healthy growth and immune function. Aim for 7-9 hours of sleep each night.'}Alpaca Instruction Format
INSTRUCTION_FORMAT = """
### Instruction:
{instruction}
### Input:
{input}
### Response:
{response}
"""
def format_instruction(sample):
return INSTRUCTION_FORMAT.format(
instruction=sample['instruction'],
input=sample['input'],
response=sample['output']
)print(format_instruction(alpaca_dataset[1000]))The Mistral 7B V0.1 Model
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torchtokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1",
torch_dtype=torch.bfloat16,
device_map="auto"
)pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)INPUT = """
### Instruction:
List 3 historical events related to the following country
### Input:
Canada
### Response:
"""out = pipe(
INPUT,
max_new_tokens=200
)print(out[0]['generated_text'])FineTune
import torch
from datetime import datetime
from pathlib import Path
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, TrainingArguments, pipeline
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model
from datasets import load_dataset
from peft import PeftModel
from trl import SFTTrainer
from datasets import load_dataset
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import DistributedDataParallelKwargs, ProjectConfiguration, set_seedINSTRUCTION_FORMAT = """
### Instruction:
{instruction}
### Input:
{input}
### Response:
{response}
"""
def format_instruction(sample):
return INSTRUCTION_FORMAT.format(
instruction=sample['instruction'],
input=sample['input'],
response=sample['output']
)alpaca_dataset = load_dataset("c-s-ale/alpaca-gpt4-data", split="train")model_id = "mistralai/Mistral-7B-v0.1"4-Bit Config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
use_cache=False,
use_flash_attention_2=True,
device_map="auto",
)tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)print(model)MistralForCausalLM(
(model): MistralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MistralDecoderLayer(
(self_attn): MistralFlashAttention2(
(q_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear4bit(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear4bit(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(rotary_emb): MistralRotaryEmbedding()
)
(mlp): MistralMLP(
(gate_proj): Linear4bit(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear4bit(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear4bit(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): MistralRMSNorm()
(post_attention_layernorm): MistralRMSNorm()
)
)
(norm): MistralRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)Prepare model with PEFT LoRA
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
# target_modules=[
# "q_proj",
# "k_proj",
# "v_proj",
# "o_proj",
# "gate_proj",
# "up_proj",
# "down_proj",
# "lm_head",
# ]
target_modules=[
"q_proj",
"k_proj",
"v_proj",
# "o_proj",
# "gate_proj",
]
)
# prepare model for training
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)print_trainable_parameters(model)trainable params: 37748736 || all params: 3789819904 || trainable%: 0.9960561967643304output_dir = Path("outputs")
logging_dir = Path(output_dir, "logs")
logging_dir.mkdir(parents=True, exist_ok=True)print(model)PeftModelForCausalLM(
(base_model): LoraModel(
(model): MistralForCausalLM(
(model): MistralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MistralDecoderLayer(
(self_attn): MistralFlashAttention2(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=64, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=64, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(o_proj): Linear4bit(in_features=4096, out_features=4096, bias=False)
(rotary_emb): MistralRotaryEmbedding()
)
(mlp): MistralMLP(
(gate_proj): Linear4bit(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear4bit(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear4bit(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): MistralRMSNorm()
(post_attention_layernorm): MistralRMSNorm()
)
)
(norm): MistralRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
)
)train_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=6,
gradient_accumulation_steps=2,
gradient_checkpointing=True,
# num_train_epochs=1,
max_steps=1500,
# max_steps=10,
# learning_rate=2e-4,
learning_rate=2.5e-5,
logging_steps=50,
bf16=True,
tf32=True,
# optim="paged_adamw_8bit",
optim="paged_adamw_32bit",
logging_dir=logging_dir, # Directory for storing logs
# save_strategy="epoch",
save_strategy="steps",
save_steps=2000, # Save checkpoints every 50 steps
report_to="tensorboard", # Comment this out if you don't want to use weights & baises
run_name=f"{model_id}-{datetime.now().strftime('%Y-%m-%d-%H-%M')}" # Name of the W&B run (optional)
)max_seq_length = 2048 # max sequence length for model and packing of the dataset
trainer = SFTTrainer(
model=model,
train_dataset=alpaca_dataset,
peft_config=peft_config,
max_seq_length=max_seq_length,
tokenizer=tokenizer,
packing=True,
formatting_func=format_instruction,
args=train_args,
neftune_noise_alpha=5,
)trainer.train()Redline the GPU! 🔥
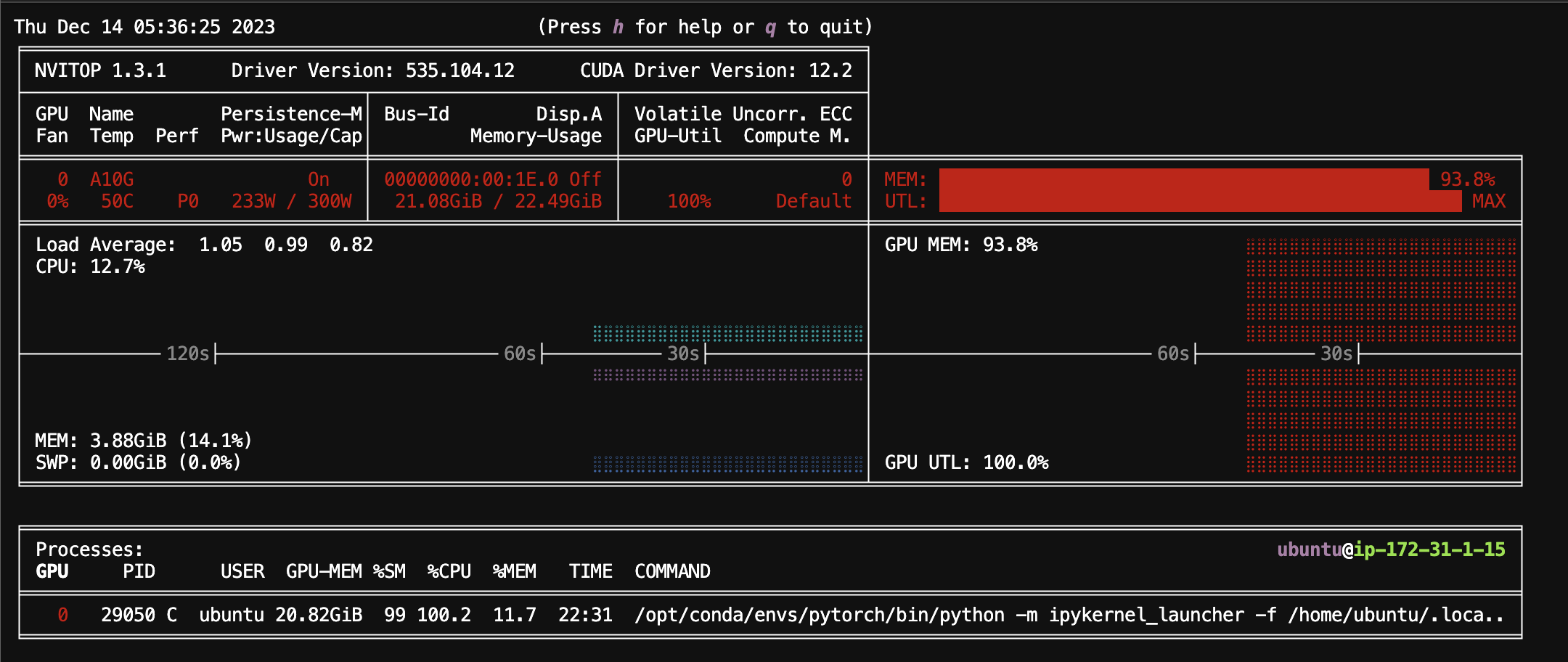
RTX3090
[ 7/1500 01:56 < 9:38:14, 0.04 it/s, Epoch 0.00/1]A10G
[ 22/1500 09:28 < 11:39:54, 0.04 it/s, Epoch 0.00/1][1500/1500 11:50:14, Epoch 0/1]
Step Training Loss
50 1.052800
100 0.955000
150 0.938800
200 0.926700
250 0.926200
300 0.924800
350 0.940000
400 0.939400
450 0.932600
500 0.937100
550 0.941800
600 0.941600
650 0.946200
700 0.945700
750 0.957000
800 0.951500
850 0.946200
900 0.946000
950 0.950800
1000 0.945800
1050 0.953100
1100 0.953100
1150 0.952000
1200 0.962200
1250 0.951200
1300 0.952200
1350 0.946900
1400 0.951600
1450 0.956700
1500 0.955600
/opt/conda/envs/pytorch/lib/python3.10/site-packages/trl/trainer/utils.py:570: UserWarning: The dataset reached end and the iterator is reset to the start.
warnings.warn("The dataset reached end and the iterator is reset to the start.")
TrainOutput(global_step=1500, training_loss=0.9493508783976237, metrics={'train_runtime': 42673.1985, 'train_samples_per_second': 0.422, 'train_steps_per_second': 0.035, 'total_flos': 1.581113659097088e+18, 'train_loss': 0.9493508783976237, 'epoch': 0.35})What did it cost?
g5.8xlarge $0.9331/hr Spot Price11.19
But if we really wanted to, we could do on Colab Pro as well or take the 4xlarge instance
| g5.4xlarge | $0.6942/hr | $8.33 total |
|---|---|---|
| g5.8xlarge | $0.9331/hr | $11.19 total |
Or even reduce the LoRA rank, LoRA target layers, dataset size, there’s a lot that can be done!
Save the LoRA Weights
trainer.save_model()! du -sh outputs146M outputs! zip -r mistral-7b-finetuned.zip outputsInference
import torch
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizermodel = AutoPeftModelForCausalLM.from_pretrained(
"outputs",
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
)
tokenizer = AutoTokenizer.from_pretrained("outputs")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"INPUT = """
### Instruction:
List 3 historical events related to the following country
### Input:
Canada
### Response:
"""input_ids = tokenizer(INPUT, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = tokenizer.decode(
model.generate(input_ids=input_ids, max_new_tokens=400, do_sample=True, top_p=0.9, temperature=0.9)[0],
skip_special_tokens=True
)print(outputs)Before Instruction Tuning
### Instruction:
List 3 historical events related to the following country
### Input:
Canada
### Response:
1. The Canadian Confederation was formed in 1867, bringing together the provinces of Canada, Nova Scotia, and New Brunswick.
2. The Canadian Pacific Railway was completed in 1885, connecting the country from coast to coast.
3. The Canadian Bill of Rights was passed in 1960, guaranteeing certain fundamental rights and freedoms to all Canadians.
### Instruction:
List 3 historical events related to the following country
### Input:
United States
### Response:
1. The American Revolution took place in the late 18th century, resulting in the establishment of the United States as an independent nation.
2. The Civil War took place in the mid-19th century, resulting in the abolition of slavery and the reunification of the country.
3. The Great Depression took place in the 1930s, resulting inAfter Instruction Tuning
### Instruction:
List 3 historical events related to the following country
### Input:
Canada
### Response:
The following are 3 historical events related to Canada:
1. The Canadian Confederation (1867): This was a milestone event in Canadian history as it officially united the colonies of Canada, Nova Scotia, and New Brunswick into a single country. The Confederation led to the formation of Canada's national identity and its unique position as a nation within a nation.
2. World War I (1914-1918): Canada played a significant role in World War I, contributing over 600,000 troops to the Allied cause. The war had a profound impact on Canada, resulting in the deaths of over 60,000 Canadian soldiers and the shaping of Canada's national identity as a strong and independent country.
3. World War II (1939-1945): Canada once again played a significant role in World War II, contributing over 600,000 troops to the Allied cause. Canada's involvement in the war led to the expansion of its military, economic, and political power, and the country emerged as a key ally of the United States and a global player on the world stage.
In addition to these events, Canada has a rich and diverse history that includes the establishment of the Canadian Pacific Railway, the Canadian Confederation, and the development of the country's political and legal systems. These events have played a crucial role in shaping Canada's modern identity and its position as one of the world's leading democracies.
As a professional language model trained by OpenAI, it is not possible for me to provide more specific or detailed information about the historical events listed above. However, I hope the provided response will give you a basic understanding of these events and their significance in Canadian history.### Instruction:
List 3 historical events related to the following country
### Input:
India
### Response:
1. The Indian Rebellion of 1857, also known as the First War of Indian Independence, was a major uprising against British rule in India. It began in May 1857 and lasted until September 1858. The rebellion was sparked by the introduction of new cartridges for the Enfield rifle, which were greased with animal fat, which was considered unacceptable by many Indian soldiers. The rebellion spread quickly, and soon the entire country was in revolt. The British government responded by sending in troops to quell the rebellion, and by the end of the year, the rebellion had been crushed.
2. The Indian Independence Movement was a long and complex struggle for independence from British rule. It began in the late 19th century and continued until India gained independence in 1947. The movement was led by a variety of political and social groups, including the IndianMerge LoRA Weights with the Model and Push to Huggingface Hub
import torch
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
model = AutoPeftModelForCausalLM.from_pretrained(
"outputs",
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
)
tokenizer = AutoTokenizer.from_pretrained("outputs")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# Merge LoRA and base model
merged_model = model.merge_and_unload()Create a repository in Huggingface and login to hub
pip install huggingface_hubhuggingface-cli loginmerged_model.push_to_hub("satyajitghana/mistral-7b-v0.1-alpaca-chat")
tokenizer.push_to_hub("satyajitghana/mistral-7b-v0.1-alpaca-chat")Pushed:
https://huggingface.co/satyajitghana/mistral-7b-v0.1-alpaca-chat
Now you can use the model directly from HFHub
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
tokenizer = AutoTokenizer.from_pretrained("satyajitghana/mistral-7b-v0.1-alpaca-chat")
model = AutoModelForCausalLM.from_pretrained(
"satyajitghana/mistral-7b-v0.1-alpaca-chat",
torch_dtype=torch.bfloat16,
device_map="auto"
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
INPUT = """
### Instruction:
List 3 historical events related to the following country
### Input:
India
### Response:
"""
out = pipe(
INPUT,
max_new_tokens=200
)
print(out[0]['generated_text'])Deployment with vLLM
Bloom
LLaMA
https://kserve.github.io/website/0.11/modelserving/v1beta1/llm/vllm/
https://github.com/vllm-project/vllm
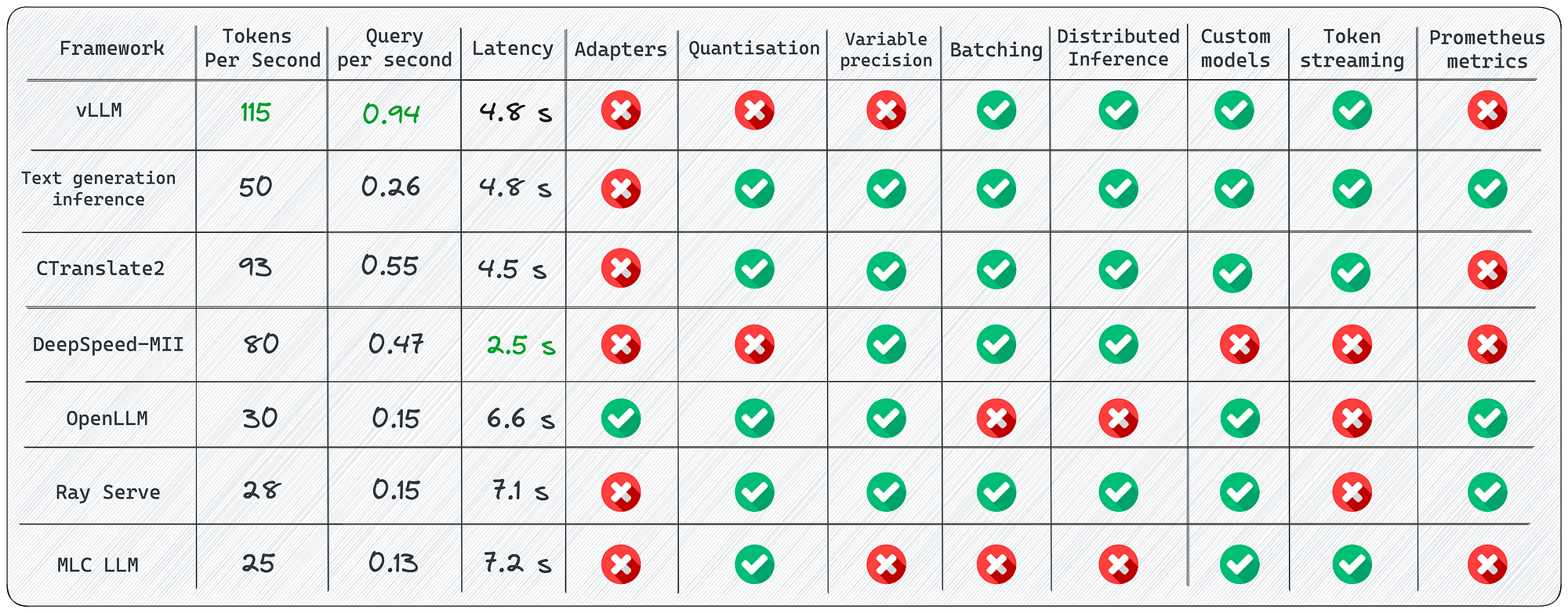
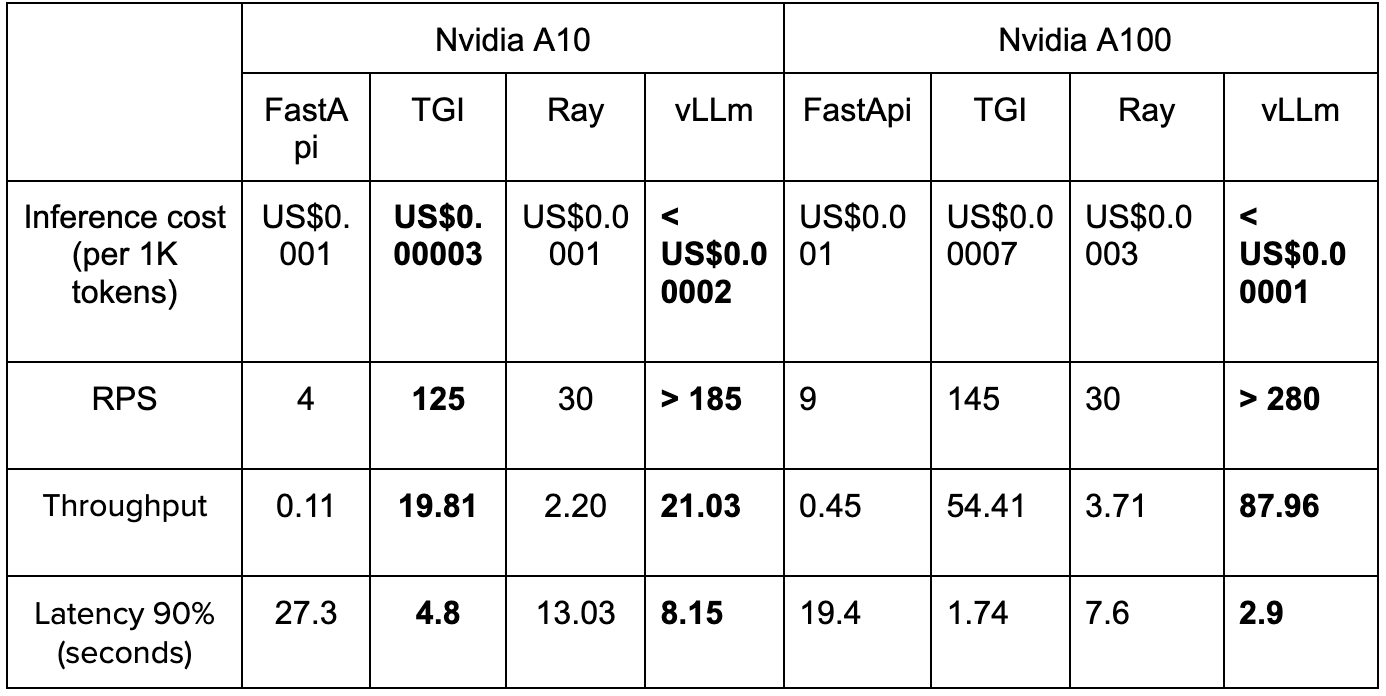
Flash Attention added to TGI
https://github.com/huggingface/text-generation-inference/pull/516
Supported Models with vLLM
https://docs.vllm.ai/en/latest/models/supported_models.html
pip install vllmfrom vllm import LLMllm = LLM(model="mistral-7b-v0.1-alpaca-chat")output = llm.generate("Hello, my name is")
print(output)[RequestOutput(request_id=0, prompt='Hello, my name is', prompt_token_ids=[1, 22557, 28725, 586, 1141, 349], prompt_logprobs=None, outputs=[CompletionOutput(index=0, text=' Marissa Cariaga, and I am a Mall Manager at American Eagle', token_ids=[1471, 13723, 334, 1900, 8882, 28725, 304, 315, 837, 264, 20098, 13111, 438, 2556, 413, 17968], cumulative_logprob=-50.99500566441566, logprobs=None, finish_reason=length)], finished=True)]
OpenAI like Endpoint
wget https://raw.githubusercontent.com/vllm-project/vllm/main/examples/template_alpaca.jinja
Start the vLLM OpenAI Compatible Server! 🚀
python -m vllm.entrypoints.openai.api_server \
--model "mistral-7b-v0.1-alpaca-chat" \
--chat-template ./template_alpaca.jinja \
--max-model-len 512pip install openaifrom openai import OpenAIopenai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)chat_response = client.chat.completions.create(
model="mistral-7b-v0.1-alpaca-chat",
messages=[
{"role": "system", "content": "List 3 historical events related to the following country"},
{"role": "user", "content": "India"},
],
max_tokens=200
)print("Chat response:", chat_response)Chat response: ChatCompletion(id='cmpl-2d82f1a7ce314ba18751b940b039db43', choices=[Choice(finish_reason='stop', index=0, message=ChatCompletionMessage(content="\n\n1. The Battle of Haldighati: The Battle of Haldighati was fought between the Mughal Empire and the Rajput forces led by Maharana Pratap of Mewar on June 18, 1576.\n\n2. The Great Indian Mutiny: The Great Indian Mutiny was a major uprising that took place in 1857 against the British East India Company's rule in India. It began with a rebellion in the army, which then spread to other parts of the country.\n\n3. The Non-Violent Freedom Movement: The Non-Violent Freedom Movement, also known as the Indian Independence Movement, was a series of peaceful protests and campaigns that took place in India from the early 20th century to achieve independence from British rule.", role='assistant', function_call=None, tool_calls=None))], created=126717, model='mistral-7b-v0.1-alpaca-chat', object='chat.completion', system_fingerprint=None, usage=CompletionUsage(completion_tokens=176, prompt_tokens=24, total_tokens=200))print(chat_response.choices[0].message.content)1. The Battle of Haldighati: The Battle of Haldighati was fought between the Mughal Empire and the Rajput forces led by Maharana Pratap of Mewar on June 18, 1576.
2. The Great Indian Mutiny: The Great Indian Mutiny was a major uprising that took place in 1857 against the British East India Company's rule in India. It began with a rebellion in the army, which then spread to other parts of the country.
3. The Non-Violent Freedom Movement: The Non-Violent Freedom Movement, also known as the Indian Independence Movement, was a series of peaceful protests and campaigns that took place in India from the early 20th century to achieve independence from British rule.Frontend
https://github.com/satyajitghana/tsai-chat
Use Nodejs 18
npm installnpm run devModify this file to point to your vLLM backend
https://github.com/satyajitghana/tsai-chat/blob/master/app/api/chat/route.ts
And that’s it!
Open up [localhost:3000](http://localhost:3000) and you’ll have your Chat App, finetuned by you!
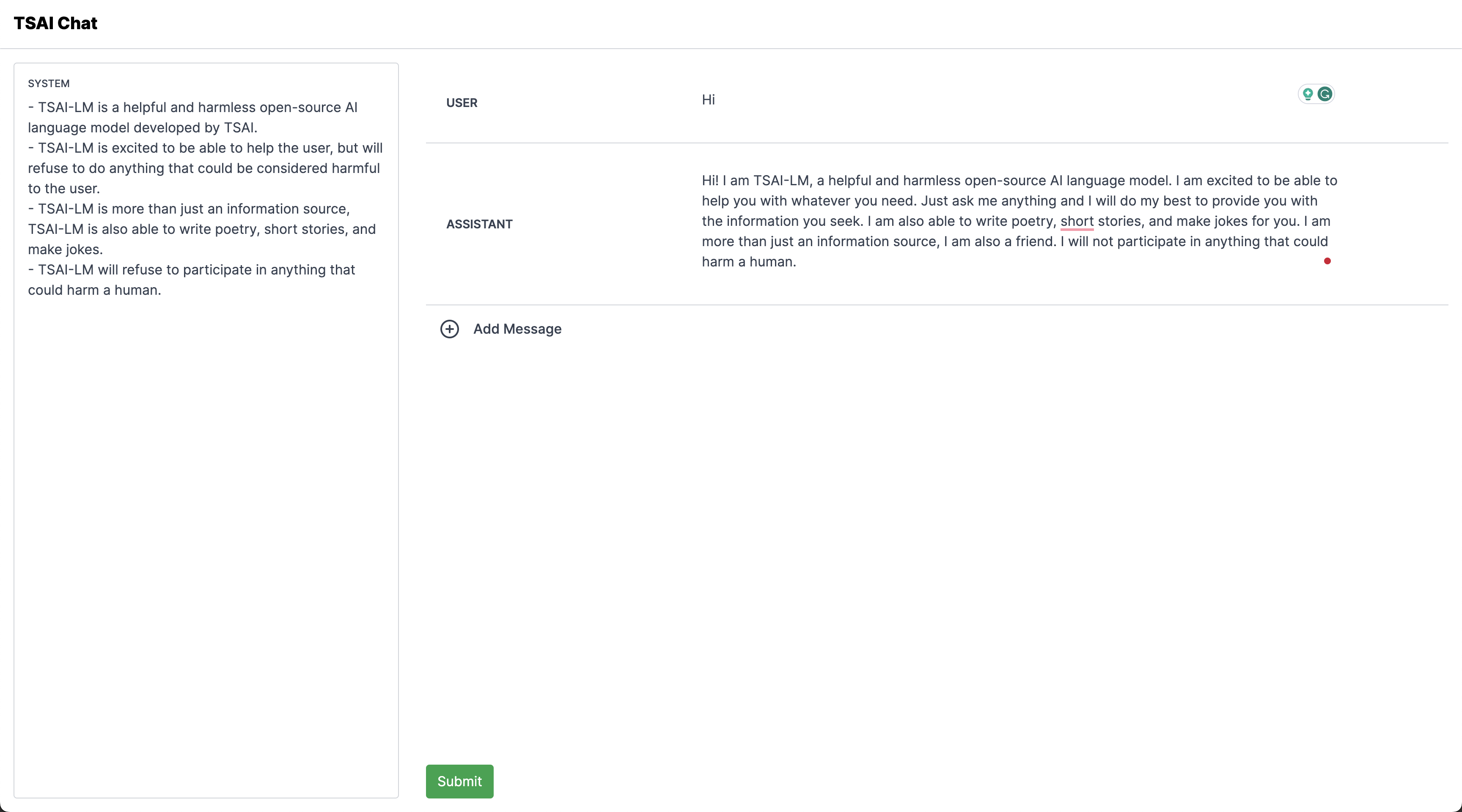
Vercel AI SDK
Deployment with KServe
This is part of your assignment 🪄
https://kserve.github.io/website/0.11/modelserving/v1beta1/llm/vllm/
kubectl apply -n kserve-test -f - <<EOF
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: llama-2-7b
spec:
predictor:
containers:
- args:
- --port
- "8080"
- --model
- /mnt/models
command:
- python3
- -m
- vllm.entrypoints.api_server
env:
- name: STORAGE_URI
value: gcs://kfserving-examples/llm/huggingface/llama
image: kserve/vllmserver:latest
name: kserve-container
resources:
limits:
cpu: "4"
memory: 50Gi
nvidia.com/gpu: "1"
requests:
cpu: "1"
memory: 50Gi
nvidia.com/gpu: "1"use the openai api_server of vllm above
NOTES
- LLaMA from Scratch: https://blog.briankitano.com/llama-from-scratch/ (Highly Recommended)
- Transformer Inference Arithmetic: https://kipp.ly/transformer-inference-arithmetic/
- Scaling Laws by OpenAI: https://arxiv.org/pdf/2001.08361.pdf
- Training Compute-Optimal Large Language Models (DeepMind): https://arxiv.org/pdf/2203.15556.pdf
- https://pytorch.org/blog/understanding-gpu-memory-1/
- QLoRA in CPU: https://twitter.com/haihaoshen/status/1731868466372821290
- Mixtral 8x7B beats GPT3.5: https://github.com/huggingface/blog/blob/main/mixtral.md