GGML and LLama.cpp
Playing around with GGML

GGML
https://github.com/ggerganov/ggml
GGML is a C library for machine learning (ML) - the "GG" refers to the initials of its originator (Georgi Gerganov). In addition to defining low-level machine learning primitives (like a tensor type), GGML defines a binary format for distributing large language models (LLMs). GGML makes use of a quantization that allows for large language models to run on consumer hardware.
- Written in C
- 16-bit float support
- Integer quantization support (4-bit, 5-bit, 8-bit, etc.)
- Automatic differentiation
- ADAM and L-BFGS optimizers
- Optimized for Apple Silicon
- On x86 architectures utilizes AVX / AVX2 intrinsics
- On ppc64 architectures utilizes VSX intrinsics
- No third-party dependencies
- Zero memory allocations during runtime
Single C File 20K lines of code: https://github.com/ggerganov/ggml/blob/master/src/ggml.c
GGUF Format
https://github.com/ggerganov/ggml/blob/master/docs/gguf.md
GGML files consists of binary-encoded data that is laid out according to a specified format. The format specifies what kind of data is present in the file, how it is represented, and the order in which it appears. The first piece of information present in a valid GGML file is a GGML version number, followed by three components that define a large language model: the model's hyperparameters, its vocabulary, and its weights. Continue reading to learn more about GGML versions and the components of a GGML model.
The model binary file contains
- Hyperparameters: n_vocab, n_embed, n_layer.
- Vocabulary: This is the tokenizer part of the model
- Weights: All the model parameters (tensors)
In GGML, a tensor consists of a number of components, including: a name, a 4-element list that represents the number of dimensions in the tensor and their lengths, and a list of the weights in that tensor. For example, consider the following 2 ⨯ 2 tensor named tensor_a0:
| tensor_a0 | |
|---|---|
| 1.0 | 0.0 |
| 0.1 | 1.1 |
A simplification of the GGML representation of tensor_a0 is {"tensor_a0", [2, 2, 1, 1], [1.0, 0.0, 0.1, 1.1]}. Note that the 4-element list of dimensions uses 1 as a placeholder for unused dimensions - this is because the product of the dimensions should not equal zero.
The weights in a GGML file are encoded as a list of layers, the length of which is typically specified in the model's hyperparameters; each layer is encoded as an ordered set of tensors.
sudo apt install build-essential cmake python3-pipgit clone https://github.com/ggerganov/ggml
cd ggmlmkdir build && cd build
cmake ..
make -jGPT-J 6B with GGML
./examples/gpt-j/download-ggml-model.sh 6B./build/bin/gpt-j -t 16 -m models/gpt-j-6B/ggml-model.bin -p "This is an example"ubuntu@ip-172-31-19-52:~/ggml$ ./build/bin/gpt-j -m models/gpt-j-6B/ggml-model.bin -p "This is an example"
main: seed = 1704383726
gptj_model_load: loading model from 'models/gpt-j-6B/ggml-model.bin' - please wait ...
gptj_model_load: n_vocab = 50400
gptj_model_load: n_ctx = 2048
gptj_model_load: n_embd = 4096
gptj_model_load: n_head = 16
gptj_model_load: n_layer = 28
gptj_model_load: n_rot = 64
gptj_model_load: ftype = 1
gptj_model_load: qntvr = 0
gptj_model_load: ggml ctx size = 12438.93 MB
gptj_model_load: memory_size = 896.00 MB, n_mem = 57344
gptj_model_load: ................................... done
gptj_model_load: model size = 11542.79 MB / num tensors = 285
extract_tests_from_file : No test file found.
test_gpt_tokenizer : 0 tests failed out of 0 tests.
main: number of tokens in prompt = 4
This is an example of a simple script that allows for the upload of a file to the same directory as the script.
#!/bin/bash
# Get the file name from standard input
FILENAME=`cat`
# Create the directory if it doesn't exist
mkdir -p `echo "$FILENAME" | sed -e 's/^.*\///'`
# Upload the file to the directory
echo `echo "$FILENAME" | sed -e 's/^.*\///'` > `echo "$FILENAME" | sed -e 's/^.*\///'`
# Change the directory to the same as the script directory
cd `echo "$FILENAME" | sed -e 's/^.*\///'`
In this example I used the filename of the script as the name of the file to be uploaded, but you can just as easily upload to any other file
main: mem per token = 15552688 bytes
main: load time = 5711.00 ms
main: sample time = 66.93 ms
main: predict time = 60642.10 ms / 298.73 ms per token
main: total time = 66875.12 msLLaMA.cpp
https://github.com/ggerganov/llama.cpp
https://github.com/ggerganov/llama.cpp/discussions/3471
https://github.com/ggerganov/llama.cpp/discussions/205
- Plain C/C++ implementation without dependencies
- Apple silicon first-class citizen - optimized via ARM NEON, Accelerate and Metal frameworks
- AVX, AVX2 and AVX512 support for x86 architectures
- Mixed F16 / F32 precision
- 2-bit, 3-bit, 4-bit, 5-bit, 6-bit and 8-bit integer quantization support
- CUDA, Metal and OpenCL GPU backend support
git clone https://github.com/ggerganov/llama.cpp
cd llama.cppmake -jOptimizing for Intel CPUs: https://www.intel.com/content/www/us/en/content-details/791610/optimizing-and-running-llama2-on-intel-cpu.html
GPU Build: https://github.com/ggerganov/llama.cpp/discussions/915
Check AVX support on CPU
grep avx /proc/cpuinfoConvert HF Models to GGUF
pip install -r requirements.txtpip install huggingface_hubWe’ll try converting the mistralai/Mistral-7B-Instruct-v0.1 into GGUF
download.py
from huggingface_hub import snapshot_download
model_id = "mistralai/Mistral-7B-Instruct-v0.1"
snapshot_download(
repo_id=model_id,
local_dir="mistral-hf",
local_dir_use_symlinks=False,
revision="main"
)python3 download.pyConvert it to GGUF
FP16
python3 convert.py mistral-hf \
--outfile mistral-7b-instruct.gguf \
--outtype f16FP32
python3 convert.py mistral-hf \
--outfile mistral-7b-instruct.gguf \
--outtype f32INT8
python3 convert.py mistral-hf \
--outfile mistral-7b-instruct.gguf \
--outtype q8_0Loading model file mistral-hf/model-00001-of-00002.safetensors
Loading model file mistral-hf/model-00001-of-00002.safetensors
Loading model file mistral-hf/model-00002-of-00002.safetensors
params = Params(n_vocab=32000, n_embd=4096, n_layer=32, n_ctx=32768, n_ff=14336, n_head=32, n_head_kv=8, n_experts=None, n_experts_used=None, f_norm_eps=1e-05, rope_scaling_type=None, f_rope_freq_base=10000.0, f_rope_scale=None, n_orig_ctx=None, rope_finetuned=None, ftype=<GGMLFileType.MostlyQ8_0: 7>, path_model=PosixPath('mistral-hf'))
32000 32000
Vocab info: <VocabLoader with 32000 base tokens and 0 added tokens>
Special vocab info: <SpecialVocab with 58980 merges, special tokens {'bos': 1, 'eos': 2, 'unk': 0}, add special tokens {'bos': True, 'eos': False}>
Permuting layer 0
Permuting layer 1
Permuting layer 2
...
Permuting layer 29
Permuting layer 30
Permuting layer 31
model.embed_tokens.weight -> token_embd.weight | BF16 | [32000, 4096]
model.layers.0.input_layernorm.weight -> blk.0.attn_norm.weight | BF16 | [4096]
model.layers.0.mlp.down_proj.weight -> blk.0.ffn_down.weight | BF16 | [4096, 14336]
model.layers.0.mlp.gate_proj.weight -> blk.0.ffn_gate.weight | BF16 | [14336, 4096]
model.layers.0.mlp.up_proj.weight -> blk.0.ffn_up.weight | BF16 | [14336, 4096]
model.layers.0.post_attention_layernorm.weight -> blk.0.ffn_norm.weight | BF16 | [4096]
model.layers.0.self_attn.k_proj.weight -> blk.0.attn_k.weight | BF16 | [1024, 4096]
...
model.layers.31.self_attn.q_proj.weight -> blk.31.attn_q.weight | BF16 | [4096, 4096]
model.layers.31.self_attn.v_proj.weight -> blk.31.attn_v.weight | BF16 | [1024, 4096]
model.norm.weight -> output_norm.weight | BF16 | [4096]
Writing mistral-7b-instruct.gguf, format 7
gguf: This GGUF file is for Little Endian only
gguf: Adding 58980 merge(s).
gguf: Setting special token type bos to 1
gguf: Setting special token type eos to 2
gguf: Setting special token type unk to 0
gguf: Setting add_bos_token to True
gguf: Setting add_eos_token to False
gguf: Setting chat_template to {{ bos_token }}{% for message in messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if message['role'] == 'user' %}{{ '[INST] ' + message['content'] + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ message['content'] + eos_token + ' ' }}{% else %}{{ raise_exception('Only user and assistant roles are supported!') }}{% endif %}{% endfor %}
[ 1/291] Writing tensor token_embd.weight | size 32000 x 4096 | type Q8_0 | T+ 18
[ 2/291] Writing tensor blk.0.attn_norm.weight | size 4096 | type F32 | T+ 18
[ 3/291] Writing tensor blk.0.ffn_down.weight | size 4096 x 14336 | type Q8_0 | T+ 18
...
[290/291] Writing tensor blk.31.attn_v.weight | size 1024 x 4096 | type Q8_0 | T+ 230
[291/291] Writing tensor output_norm.weight | size 4096 | type F32 | T+ 230
Wrote mistral-7b-instruct.gguf7.2G mistral-7b-instruct.ggufChat Model
./main -m ./mistral-7b-instruct.gguf -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt❯ ./main -m ./mistral-7b-instruct.gguf -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
Log start
main: build = 1742 (edd1ab7)
main: built with cc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0 for x86_64-linux-gnu
main: seed = 1704215892
llama_model_loader: loaded meta data with 23 key-value pairs and 291 tensors from ./mistral-7b-instruct.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = .
llama_model_loader: - kv 2: llama.context_length u32 = 32768
llama_model_loader: - kv 3: llama.embedding_length u32 = 4096
llama_model_loader: - kv 4: llama.block_count u32 = 32
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 14336
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 8
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 10: llama.rope.freq_base f32 = 10000.000000
llama_model_loader: - kv 11: general.file_type u32 = 7
llama_model_loader: - kv 12: tokenizer.ggml.model str = llama
llama_model_loader: - kv 13: tokenizer.ggml.tokens arr[str,32000] = ["<unk>", "<s>", "</s>", "<0x00>", "<...
llama_model_loader: - kv 14: tokenizer.ggml.scores arr[f32,32000] = [0.000000, 0.000000, 0.000000, 0.0000...
llama_model_loader: - kv 15: tokenizer.ggml.token_type arr[i32,32000] = [2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, ...
llama_model_loader: - kv 16: tokenizer.ggml.merges arr[str,58980] = ["▁ t", "i n", "e r", "▁ a", "h e...
llama_model_loader: - kv 17: tokenizer.ggml.bos_token_id u32 = 1
llama_model_loader: - kv 18: tokenizer.ggml.eos_token_id u32 = 2
llama_model_loader: - kv 19: tokenizer.ggml.unknown_token_id u32 = 0
llama_model_loader: - kv 20: tokenizer.ggml.add_bos_token bool = true
llama_model_loader: - kv 21: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 22: tokenizer.chat_template str = {{ bos_token }}{% for message in mess...
llama_model_loader: - type f32: 65 tensors
llama_model_loader: - type q8_0: 226 tensors
llm_load_vocab: special tokens definition check successful ( 259/32000 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 32768
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 8
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_gqa = 4
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: n_ff = 14336
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 10000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_yarn_orig_ctx = 32768
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = Q8_0
llm_load_print_meta: model params = 7.24 B
llm_load_print_meta: model size = 7.17 GiB (8.50 BPW)
llm_load_print_meta: general.name = .
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.11 MiB
llm_load_tensors: system memory used = 7338.75 MiB
...................................................................................................
llama_new_context_with_model: n_ctx = 512
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: KV self size = 64.00 MiB, K (f16): 32.00 MiB, V (f16): 32.00 MiB
llama_build_graph: non-view tensors processed: 676/676
llama_new_context_with_model: compute buffer total size = 76.19 MiB
system_info: n_threads = 8 / 16 | AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 |
main: interactive mode on.
Reverse prompt: 'User:'
sampling:
repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000
top_k = 40, tfs_z = 1.000, top_p = 0.950, min_p = 0.050, typical_p = 1.000, temp = 0.800
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampling order:
CFG -> Penalties -> top_k -> tfs_z -> typical_p -> top_p -> min_p -> temp
generate: n_ctx = 512, n_batch = 512, n_predict = 256, n_keep = 0
== Running in interactive mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to LLaMa.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
Transcript of a dialog, where the User interacts with an Assistant named Bob. Bob is helpful, kind, honest, good at writing, and never fails to answer the User's requests immediately and with precision.
User: Hello, Bob.
Bob: Hello. How may I help you today?
User: Please tell me the largest city in Europe.
Bob: Sure. The largest city in Europe is Moscow, the capital of Russia.
User: What is the difference between an interpreted computer language and a compiled computer language?
Bob: An interpreted computer language is a programming language that is executed line by line by an interpreter, which translates the code as it runs. A compiled computer language, on the other hand, is translated into machine code that can be directly executed by a computer's processor at compile time.
User:llama_print_timings: load time = 55413.81 ms
llama_print_timings: sample time = 2.65 ms / 64 runs ( 0.04 ms per token, 24123.63 tokens per second)
llama_print_timings: prompt eval time = 7868.02 ms / 117 tokens ( 67.25 ms per token, 14.87 tokens per second)
llama_print_timings: eval time = 15581.52 ms / 63 runs ( 247.33 ms per token, 4.04 tokens per second)
llama_print_timings: total time = 137072.03 ms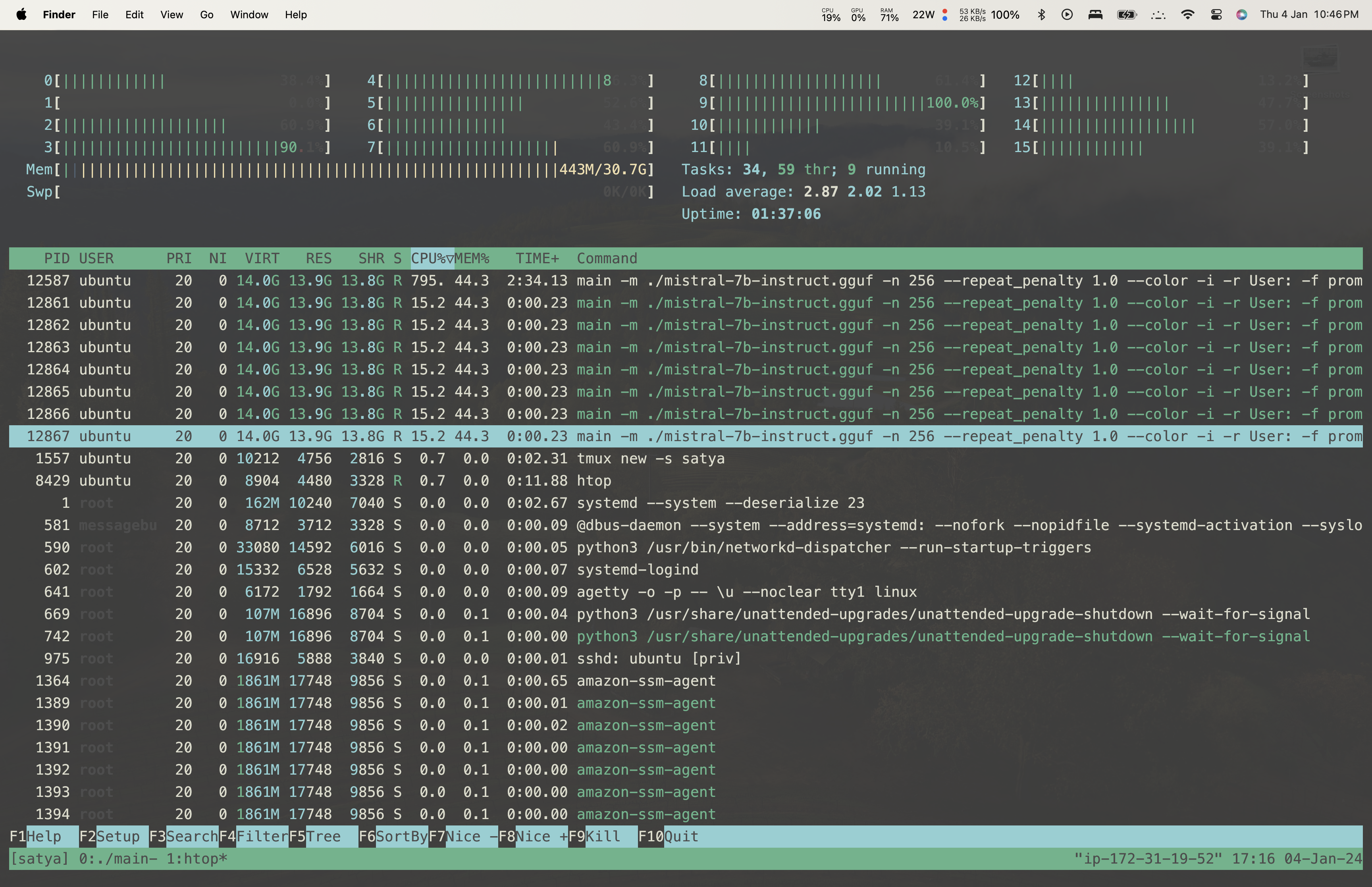
Notice something? The RAM Usage!
Also, try running it again
llama_print_timings: load time = 1369.10 msSee? The load time was 55s before, now its just 1.3s!
for Mixtral
download.py
from huggingface_hub import snapshot_download
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
snapshot_download(
repo_id=model_id,
local_dir="mixtral-hf",
local_dir_use_symlinks=False,
revision="main"
)Mixtral 8x7B GGUF Files: https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/tree/main
Mistral 7B GGUF Files: https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF
Quantization in GGML
https://github.com/ggerganov/llama.cpp/pull/1684
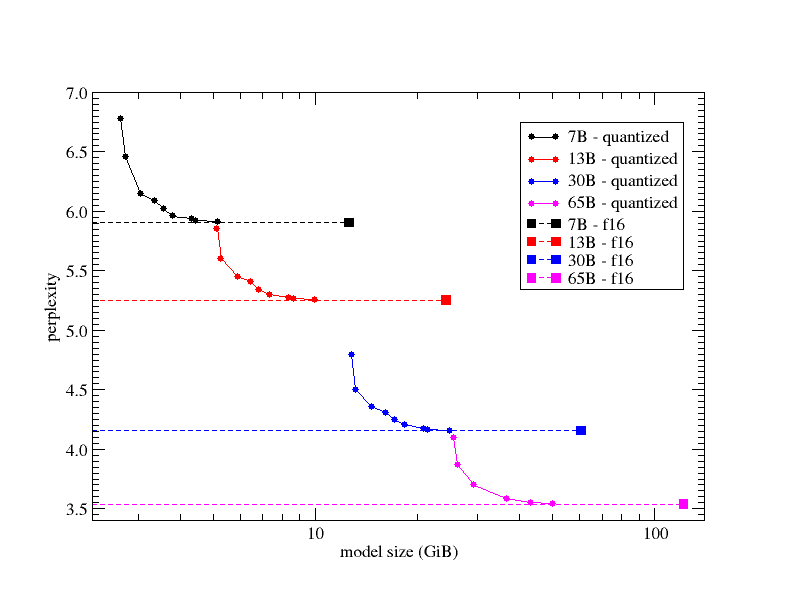
In the existing ggml quantization types we have "type-0" (Q4_0, Q5_0) and "type-1" (Q4_1, Q5_1). In "type-0", weights w are obtained from quants q using w = d * q, where d is the block scale. In "type-1", weights are given by w = d * q + m, where m is the block minimum.
The following new quantization types are added to ggml:
GGML_TYPE_Q2_K- "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using2.5625bits per weight (bpw)
(16*2 + 4+4+1)/16 = 2.5625GGML_TYPE_Q3_K- "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using3.4375bpw.GGML_TYPE_Q4_K- "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using4.5bpw.GGML_TYPE_Q5_K- "type-1" 5-bit quantization. Same super-block structure asGGML_TYPE_Q4_Kresulting in5.5bpwGGML_TYPE_Q6_K- "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using6.5625bpwGGML_TYPE_Q8_K- "type-0" 8-bit quantization. Only used for quantizing intermediate results. The difference to the existingQ8_0is that the block size is 256. All 2-6 bit dot products are implemented for this quantization type.
This is exposed via llama.cpp quantization types that define various "quantization mixes" as follows:
LLAMA_FTYPE_MOSTLY_Q2_K- usesGGML_TYPE_Q4_Kfor theattention.vwandfeed_forward.w2tensors,GGML_TYPE_Q2_Kfor the other tensors.LLAMA_FTYPE_MOSTLY_Q3_K_S- usesGGML_TYPE_Q3_Kfor all tensorsLLAMA_FTYPE_MOSTLY_Q3_K_M- usesGGML_TYPE_Q4_Kfor theattention.wv,attention.wo, andfeed_forward.w2tensors, elseGGML_TYPE_Q3_KLLAMA_FTYPE_MOSTLY_Q3_K_L- usesGGML_TYPE_Q5_Kfor theattention.wv,attention.wo, andfeed_forward.w2tensors, elseGGML_TYPE_Q3_KLLAMA_FTYPE_MOSTLY_Q4_K_S- usesGGML_TYPE_Q4_Kfor all tensorsLLAMA_FTYPE_MOSTLY_Q4_K_M- usesGGML_TYPE_Q6_Kfor half of theattention.wvandfeed_forward.w2tensors, elseGGML_TYPE_Q4_KLLAMA_FTYPE_MOSTLY_Q5_K_S- usesGGML_TYPE_Q5_Kfor all tensorsLLAMA_FTYPE_MOSTLY_Q5_K_M- usesGGML_TYPE_Q6_Kfor half of theattention.wvandfeed_forward.w2tensors, elseGGML_TYPE_Q5_KLLAMA_FTYPE_MOSTLY_Q6_Kuses 6-bit quantization (GGML_TYPE_Q8_K) for all tensors
_S, _M, and _L stand for Small, Medium, and Large
static const std::vector<struct quant_option> QUANT_OPTIONS = {
{ "Q4_0", LLAMA_FTYPE_MOSTLY_Q4_0, " 3.56G, +0.2166 ppl @ LLaMA-v1-7B", },
{ "Q4_1", LLAMA_FTYPE_MOSTLY_Q4_1, " 3.90G, +0.1585 ppl @ LLaMA-v1-7B", },
{ "Q5_0", LLAMA_FTYPE_MOSTLY_Q5_0, " 4.33G, +0.0683 ppl @ LLaMA-v1-7B", },
{ "Q5_1", LLAMA_FTYPE_MOSTLY_Q5_1, " 4.70G, +0.0349 ppl @ LLaMA-v1-7B", },
{ "Q2_K", LLAMA_FTYPE_MOSTLY_Q2_K, " 2.63G, +0.6717 ppl @ LLaMA-v1-7B", },
{ "Q3_K", LLAMA_FTYPE_MOSTLY_Q3_K_M, "alias for Q3_K_M" },
{ "Q3_K_S", LLAMA_FTYPE_MOSTLY_Q3_K_S, " 2.75G, +0.5551 ppl @ LLaMA-v1-7B", },
{ "Q3_K_M", LLAMA_FTYPE_MOSTLY_Q3_K_M, " 3.07G, +0.2496 ppl @ LLaMA-v1-7B", },
{ "Q3_K_L", LLAMA_FTYPE_MOSTLY_Q3_K_L, " 3.35G, +0.1764 ppl @ LLaMA-v1-7B", },
{ "Q4_K", LLAMA_FTYPE_MOSTLY_Q4_K_M, "alias for Q4_K_M", },
{ "Q4_K_S", LLAMA_FTYPE_MOSTLY_Q4_K_S, " 3.59G, +0.0992 ppl @ LLaMA-v1-7B", },
{ "Q4_K_M", LLAMA_FTYPE_MOSTLY_Q4_K_M, " 3.80G, +0.0532 ppl @ LLaMA-v1-7B", },
{ "Q5_K", LLAMA_FTYPE_MOSTLY_Q5_K_M, "alias for Q5_K_M", },
{ "Q5_K_S", LLAMA_FTYPE_MOSTLY_Q5_K_S, " 4.33G, +0.0400 ppl @ LLaMA-v1-7B", },
{ "Q5_K_M", LLAMA_FTYPE_MOSTLY_Q5_K_M, " 4.45G, +0.0122 ppl @ LLaMA-v1-7B", },
{ "Q6_K", LLAMA_FTYPE_MOSTLY_Q6_K, " 5.15G, -0.0008 ppl @ LLaMA-v1-7B", },
{ "Q8_0", LLAMA_FTYPE_MOSTLY_Q8_0, " 6.70G, +0.0004 ppl @ LLaMA-v1-7B", },
{ "F16", LLAMA_FTYPE_MOSTLY_F16, "13.00G @ 7B", },
{ "F32", LLAMA_FTYPE_ALL_F32, "26.00G @ 7B", },
// Note: Ensure COPY comes after F32 to avoid ftype 0 from matching.
{ "COPY", LLAMA_FTYPE_ALL_F32, "only copy tensors, no quantizing", },
};./quantize ./mistral-7b-instruct.gguf ./mistral-7b-instruct.gguf-q4_0.gguf q4_0hist: 0.036 0.016 0.025 0.039 0.056 0.077 0.096 0.112 0.117 0.112 0.097 0.077 0.056 0.039 0.025 0.021
[ 289/ 291] blk.31.attn_q.weight - [ 4096, 4096, 1, 1], type = f16, quantizing to q4_0 .. size = 32.00 MiB -> 9.00 MiB | hist: 0.036 0.015 0.024 0.038 0.055 0.076 0.097 0.114 0.121 0.114 0.097 0.076 0.055 0.038 0.024 0.020
[ 290/ 291] blk.31.attn_v.weight - [ 4096, 1024, 1, 1], type = f16, quantizing to q4_0 .. size = 8.00 MiB -> 2.25 MiB | hist: 0.036 0.014 0.022 0.035 0.052 0.074 0.098 0.119 0.130 0.119 0.098 0.074 0.052 0.035 0.023 0.019
[ 291/ 291] output_norm.weight - [ 4096, 1, 1, 1], type = f32, size = 0.016 MB
llama_model_quantize_internal: model size = 13813.02 MB
llama_model_quantize_internal: quant size = 3917.87 MB
llama_model_quantize_internal: hist: 0.036 0.015 0.024 0.038 0.055 0.076 0.097 0.113 0.122 0.113 0.097 0.076 0.055 0.038 0.024 0.020
main: quantize time = 7258.20 ms
main: total time = 7258.20 ms./main -m ./mistral-7b-instruct.gguf -n 64 -p "in the coming years differentiating beween artificial intelligence and intelligence would" -ellama_print_timings: eval time = 22658.86 ms / 63 runs ( 359.66 ms per token, 2.78 tokens per second)./main -m ./mistral-7b-instruct.gguf-q4_0.gguf -n 64 -p "in the coming years differentiating beween artificial intelligence and intelligence would" -ellama_print_timings: eval time = 6687.53 ms / 63 runs ( 106.15 ms per token, 9.42 tokens per secondBNF Grammar
https://github.com/ggerganov/llama.cpp/blob/master/grammars/README.md
This is an incredibly powerful technique for working with a Large Language Model. Effectively it lets you insert custom code into the model's output generation process, ensuring that the overall output exactly matches the grammar that you specify.
This works by directly modifying the next-token selection logic, restricting the model to only being able to pick from the tokens that fulfill the rules of the grammar at any given point.
The most exciting possibility for this in my opinion is building a version of OpenAI Functions on top of models like Llama 2 that can run on your own device.
JSON Grammar
./main -m ./mistral-7b-instruct.gguf -n 256 --grammar-file grammars/json.gbnf -p 'Request: schedule an event on 28th january 2024 at 8am, for a duration of 1 hour, title being RAG Workshop, you must use the ISO time format, fields should be datetime, duration, title in the json; JSON:'Request: schedule an event on 28th january 2024 at 8am, for a duration of 1 hour, title being RAG Workshop, you must use the ISO time format, fields should be datetime, duration, title in the json; Command:{"datetime":"2024-01-28T08:00:00","duration": "PT1H", "title":"RAG Workshop"} [end of text]That’s a valid JSON!
C Code Grammar
Might not work with this instruct model
./main -m ./mistral-7b-instruct.gguf -n 256 --grammar-file grammars/c.gbnf -p 'Request: Write a C code to read a text file, and convert all characters to uppercase; Code: #include <stdio.h>'You can build your own grammar!
https://grammar.intrinsiclabs.ai/
With Python
pip install -U llama-cpp-pythonfrom llama_cpp.llama import Llama, LlamaGrammar
import httpx
grammar_text = httpx.get("https://raw.githubusercontent.com/ggerganov/llama.cpp/master/grammars/json_arr.gbnf").text
grammar = LlamaGrammar.from_string(grammar_text)llm = Llama("mistral-7b-instruct.gguf")response = llm(
"JSON list of name strings of attractions in SF:",
grammar=grammar, max_tokens=-1
)import json
print(json.dumps(json.loads(response['choices'][0]['text']), indent=4))[
{
"address": {
"country": "US",
"locality": "San Francisco",
"postal_code": 94103,
"region": "CA",
"route": "Museum Way",
"street_number": 151
},
"geocode": {
"latitude": 37.782569,
"longitude": -122.406605
},
"name": "SFMOMA",
"phone": "(415) 357-4000",
"website": "http://www.sfmoma.org/"
},
{
"address": {
"country": "US",
"locality": "San Francisco",
"postal_code": 94129,
"region": "CA",
"route": "The Presidio",
"street_number": 104
},
"geocode": {
"latitude": 37.806566,
"longitude": -122.440633
},
"name": "Walt Disney Family Museum",
"phone": "(415) 345-6800",
"website": "http://www.waltdisney.org/museum"
}
]Docker Support
https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#docker
LLaMa.cpp Server
./server -m ./mistral-7b-instruct.gguf -c 2048 --host 0.0.0.0./server -m ./mistral-7b-instruct.gguf-q4_0.gguf -c 2048 --host 0.0.0.0curl --request POST \
--url http://localhost:8080/completion \
--header "Content-Type: application/json" \
--data '{"prompt": "Building a website can be done in 10 simple steps:", "n_predict": 128}'{
"content": "\n\n1. Define the purpose and scope of your website: Before you start building a website, you need to decide what it is for and what it will do. This will help you determine the features and functionality that are necessary.\n2. Choose a platform: There are many platforms available for building a website, such as WordPress, Wix, Squarespace, and more. Each platform has its own strengths and weaknesses, so it's important to choose one that fits your needs.\n3. Select a domain name: Your domain name is the online address where people will find your website. Choose a name that is",
"generation_settings": {
"frequency_penalty": 0,
"grammar": "",
"ignore_eos": false,
"logit_bias": [],
"min_p": 0.05000000074505806,
"mirostat": 0,
"mirostat_eta": 0.10000000149011612,
"mirostat_tau": 5,
"model": "./mistral-7b-instruct.gguf",
"n_ctx": 2048,
"n_keep": 0,
"n_predict": 128,
"n_probs": 0,
"penalize_nl": true,
"penalty_prompt_tokens": [],
"presence_penalty": 0,
"repeat_last_n": 64,
"repeat_penalty": 1.100000023841858,
"seed": 4294967295,
"stop": [],
"stream": false,
"temperature": 0.800000011920929,
"tfs_z": 1,
"top_k": 40,
"top_p": 0.949999988079071,
"typical_p": 1,
"use_penalty_prompt_tokens": false
},
"model": "./mistral-7b-instruct.gguf",
"prompt": "Building a website can be done in 10 simple steps:",
"slot_id": 0,
"stop": true,
"stopped_eos": false,
"stopped_limit": true,
"stopped_word": false,
"stopping_word": "",
"timings": {
"predicted_ms": 31733.496,
"predicted_n": 128,
"predicted_per_second": 4.033592768978243,
"predicted_per_token_ms": 247.9179375,
"prompt_ms": 1447.424,
"prompt_n": 14,
"prompt_per_second": 9.672355854262468,
"prompt_per_token_ms": 103.38742857142857
},
"tokens_cached": 142,
"tokens_evaluated": 14,
"tokens_predicted": 128,
"truncated": false
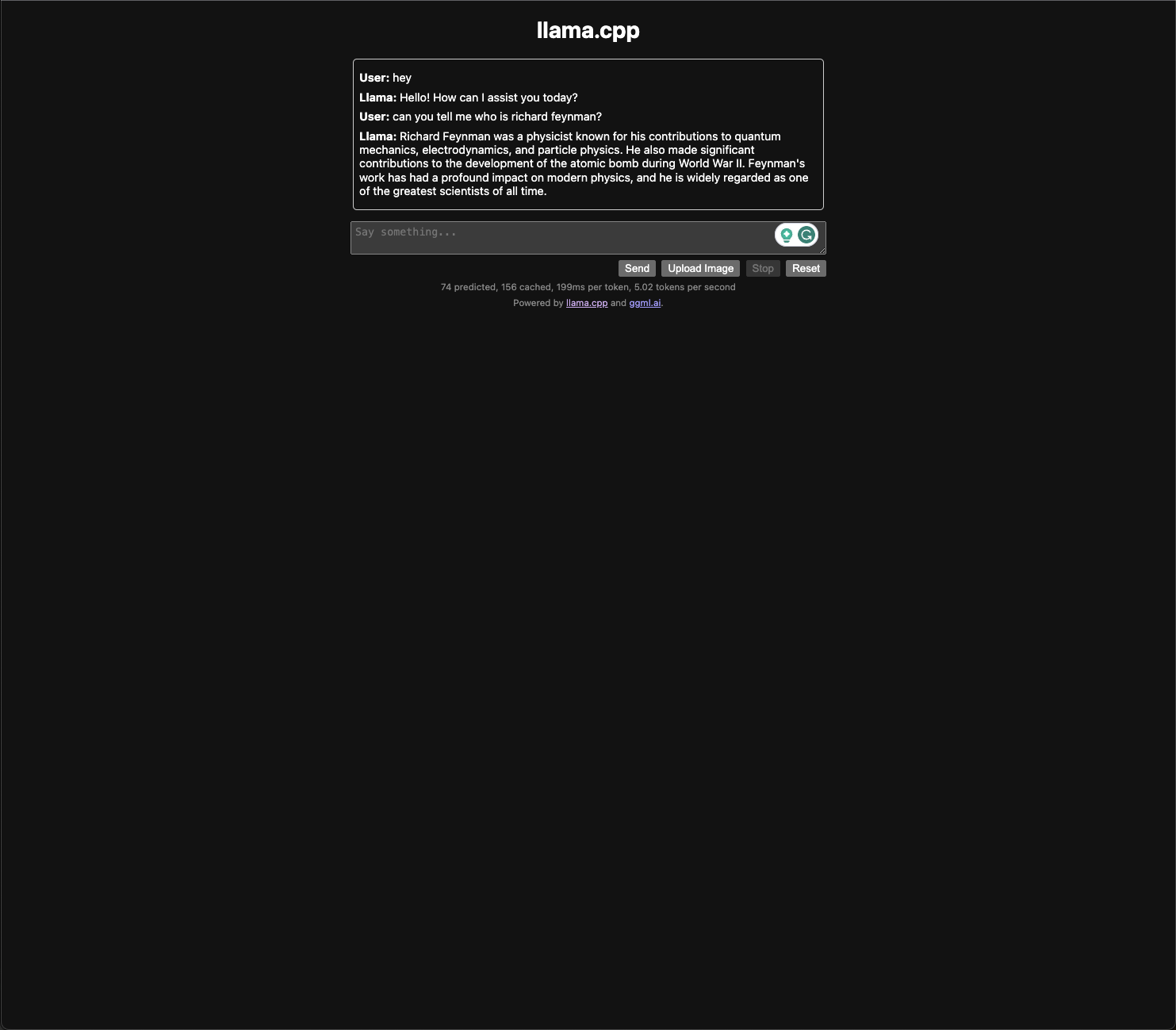
}It also comes with a web ui ;)
With OpenAI Client
pip install openaiimport openai
client = openai.OpenAI(
base_url="http://localhost:8080/v1",
api_key = "NONE"
)
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a CTO Coach AI, designed to support and guide current or aspiring CTOs in understanding their roles, responsibilities, and best practices. Help users develop the skills and knowledge needed to excel as a CTO, including leadership, strategic planning, team management, and technological expertise. Offer personalized advice and mentorship to enhance their professional growth and assist them in overcoming challenges they may face in their journey from a senior software developer to a successful CTO."},
{"role": "user", "content": "Is redis really a glorified mmap?"}
]
)
print(completion.choices[0].message)ChatCompletionMessage(content='Redis is a distributed in-memory data structure store that can be used as a database, cache, and message broker. While it does use memory mapping to store data on disk, it also provides many other features such as persistence, clustering, and transactions that make it more than just a glorified mmap. Additionally, Redis is designed to handle high-performance workloads and can scale horizontally across multiple machines, making it a popular choice for many applications.', role='assistant', function_call=None, tool_calls=None)https://github.com/mustvlad/ChatGPT-System-Prompts/blob/main/prompts/educational/python-tutor.md
Any frontend that support OpenAI API’s for chat can use this backend directly!
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.7/install.sh | bashnvm install 18npx create-next-app --example https://github.com/vercel/ai/tree/main/examples/next-openai next-openai-appcd next-openai-appmodify app/api/chat/route.ts and add the baseURL
--- a/app/api/chat/route.ts
+++ b/app/api/chat/route.ts
@@ -4,6 +4,7 @@ import { OpenAIStream, StreamingTextResponse } from 'ai';
// Create an OpenAI API client (that's edge friendly!)
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY || '',
+ baseURL: 'http://localhost:8080/v1'
});npm run devOpen http://35.89.99.169:3000/
The UI seems 😭
Here’s a better one
git clone https://github.com/satyajitghana/next-openai-llama-chat
cd next-openai-llama-chatnpm run dev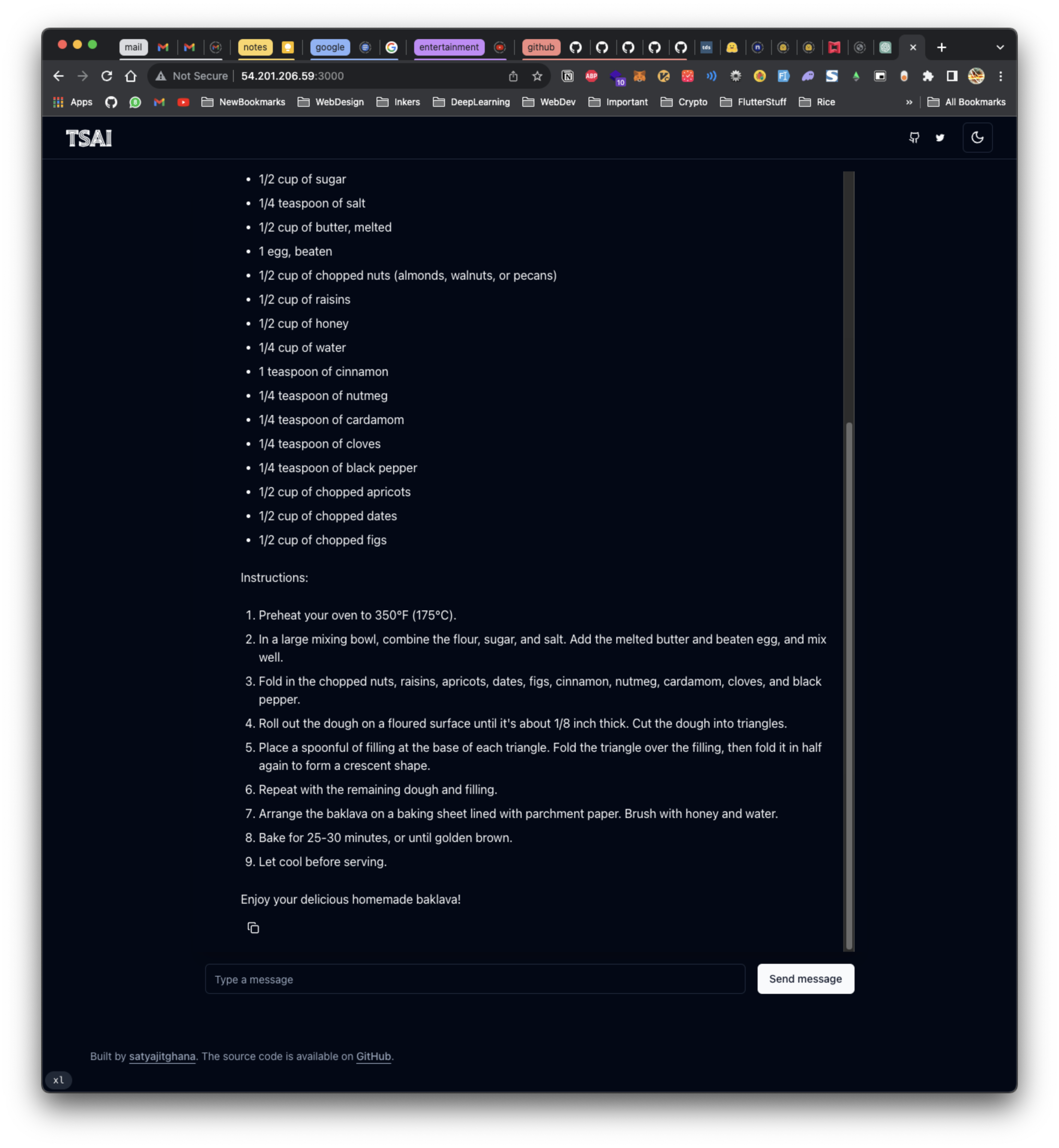
You can constrain the grammar in llama.cpp server api by modifying the api/chat/route.ts like this
import OpenAI from "openai";
import { OpenAIStream, StreamingTextResponse } from "ai";
import { siteConfig } from "@/config/site";
// Create an OpenAI API client (that's edge friendly!)
const openai = new OpenAI({
apiKey: "NONE",
// baseURL: "http://localhost:8000/v1"
baseURL: siteConfig.modelBackend,
});
// IMPORTANT! Set the runtime to edge
export const runtime = 'edge';
const grammar = `root ::= object
value ::= object | array | string | number | ("true" | "false" | "null") ws
object ::=
"{" ws (
string ":" ws value
("," ws string ":" ws value)*
)? "}" ws
array ::=
"[" ws (
value
("," ws value)*
)? "]" ws
string ::=
"\\"" (
[^"\\\\] |
"\\\\" (["\\\\/bfnrt] | "u" [0-9a-fA-F] [0-9a-fA-F] [0-9a-fA-F] [0-9a-fA-F]) # escapes
)* "\\"" ws
number ::= ("-"? ([0-9] | [1-9] [0-9]*)) ("." [0-9]+)? ([eE] [-+]? [0-9]+)? ws
# Optional space: by convention, applied in this grammar after literal chars when allowed
ws ::= ([ \\t\\n] ws)?`
export async function POST(req: Request) {
const { messages } = await req.json();
// Ask OpenAI for a streaming chat completion given the prompt
const response = await openai.chat.completions.create({
model: 'gpt-3.5-turbo',
stream: true,
messages,
grammar: grammar
} as any);
// Convert the response into a friendly text-stream
const stream = OpenAIStream(response as any);
// Respond with the stream
return new StreamingTextResponse(stream);
}NOTE: The backslash has to be escaped with another backslash in the grammar file, so \t becomes \\t and \ becomes \\ and \\ becomes \\\\
GGUF Quantized Weights for Mistral
https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/tree/main
LLaVA
https://github.com/ggerganov/llama.cpp/tree/master/examples/llava
sudo apt-get install git-lfs
git-lfs installgit clone https://huggingface.co/liuhaotian/llava-v1.5-7b
git clone https://huggingface.co/openai/clip-vit-large-patch14-336python3 ./examples/llava/llava-surgery.py -m ../llava-v1.5-7bubuntu@ip-172-31-12-212:~/llama.cpp$ python3 ./examples/llava/llava-surgery.py -m ../llava-v1.5-7b
Done!
Now you can convert ../llava-v1.5-7b to a a regular LLaMA GGUF file.
Also, use ../llava-v1.5-7b/llava.projector to prepare a llava-encoder.gguf file.pip install pillowpython3 ./examples/llava/convert-image-encoder-to-gguf.py -m ../clip-vit-large-patch14-336 --llava-projector ../llava-v1.5-7b/llava.projector --output-dir ../llava-v1.5-7bv.blk.22.ln1.bias - f32 - shape = (1024,)
Converting to float16
v.blk.22.ffn_down.weight - f16 - shape = (4096, 1024)
Converting to float32
v.blk.22.ffn_down.bias - f32 - shape = (4096,)
Converting to float16
v.blk.22.ffn_up.weight - f16 - shape = (1024, 4096)
Converting to float32
v.blk.22.ffn_up.bias - f32 - shape = (1024,)
Converting to float32
v.blk.22.ln2.weight - f32 - shape = (1024,)
Converting to float32
v.blk.22.ln2.bias - f32 - shape = (1024,)
skipping parameter: vision_model.post_layernorm.weight
skipping parameter: vision_model.post_layernorm.bias
skipping parameter: visual_projection.weight
skipping parameter: text_projection.weight
Done. Output file: ../llava-v1.5-7b/mmproj-model-f16.ggufpython3 ./convert.py ../llava-v1.5-7bWriting ../llava-v1.5-7b/ggml-model-f16.gguf, format 1
gguf: This GGUF file is for Little Endian only
gguf: WARNING: Adding merges requested but no merges found, output may be non-functional.
gguf: Setting special token type bos to 1
gguf: Setting special token type eos to 2
gguf: Setting special token type pad to 0
gguf: Setting add_bos_token to True
gguf: Setting add_eos_token to False
[ 1/291] Writing tensor token_embd.weight
...
[287/291] Writing tensor blk.31.ffn_down.weight | size 4096 x 11008 | type F16 | T+ 61
[288/291] Writing tensor blk.31.attn_norm.weight | size 4096 | type F32 | T+ 61
[289/291] Writing tensor blk.31.ffn_norm.weight | size 4096 | type F32 | T+ 61
[290/291] Writing tensor output_norm.weight | size 4096 | type F32 | T+ 61
[291/291] Writing tensor output.weight | size 32000 x 4096 | type F16 | T+ 61
Wrote ../llava-v1.5-7b/ggml-model-f16.ggufggml-model-f16.gguf
mmproj-model-f16.ggufmake llava-cliwget http://images.cocodataset.org/val2017/000000039769.jpg./llava-cli -m ../llava-v1.5-7b/ggml-model-f16.gguf --mmproj ../llava-v1.5-7b/mmproj-model-f16.gguf --image ./000000039769.jpg...................................................................................................
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: KV self size = 1024.00 MiB, K (f16): 512.00 MiB, V (f16): 512.00 MiB
llama_build_graph: non-view tensors processed: 676/676
llama_new_context_with_model: compute buffer total size = 159.19 MiB
encode_image_with_clip: image encoded in 2569.83 ms by CLIP ( 4.46 ms per image patch)
In the image, two cats are lying down on a pink and white blanket placed on a couch. One cat is positioned towards the left side of the blanket, while the other cat is on the right side, occupying a larger portion of the blanket than the first cat. The couch appears to be covered in red fabric, providing a comfortable setting for the two cats to rest together.
llama_print_timings: load time = 7382.40 ms
llama_print_timings: sample time = 28.03 ms / 87 runs ( 0.32 ms per token, 3104.15 tokens per second)
llama_print_timings: prompt eval time = 52327.79 ms / 617 tokens ( 84.81 ms per token, 11.79 tokens per second)
llama_print_timings: eval time = 30936.54 ms / 87 runs ( 355.59 ms per token, 2.81 tokens per second)
llama_print_timings: total time = 87689.00 mswith a custom prompt
./llava-cli -m ../llava-v1.5-7b/ggml-model-f16.gguf --mmproj ../llava-v1.5-7b/mmproj-model-f16.gguf --image ./000000039769.jpg -p "how many cats are there in this image?"...................................................................................................
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: KV self size = 1024.00 MiB, K (f16): 512.00 MiB, V (f16): 512.00 MiB
llama_build_graph: non-view tensors processed: 676/676
llama_new_context_with_model: compute buffer total size = 159.19 MiB
encode_image_with_clip: image encoded in 2572.95 ms by CLIP ( 4.47 ms per image patch)
There are two cats in this image.
llama_print_timings: load time = 7376.47 ms
llama_print_timings: sample time = 2.78 ms / 10 runs ( 0.28 ms per token, 3594.54 tokens per second)
llama_print_timings: prompt eval time = 53057.42 ms / 626 tokens ( 84.76 ms per token, 11.80 tokens per second)
llama_print_timings: eval time = 3542.04 ms / 10 runs ( 354.20 ms per token, 2.82 tokens per second)
llama_print_timings: total time = 60969.17 msLLaVA Server
./server -m ../llava-v1.5-7b/ggml-model-f16.gguf --mmproj ../llava-v1.5-7b/mmproj-model-f16.ggufllava_api.py
import requests
import base64
import io
import json
import argparse
url = "http://localhost:8080/completion"
headers = {"Content-Type": "application/json"}
# Create the parser and add argument
parser = argparse.ArgumentParser()
parser.add_argument('--path', required=True, help='Path to the image file')
args = parser.parse_args()
# Open the image file in binary mode and convert to base64
with open(args.path, 'rb') as file:
encoded_string = base64.b64encode(file.read()).decode('utf-8')
image_data = [{"data": encoded_string, "id": 12}]
data = {"prompt": "USER:[img-12]Describe the image.\nASSISTANT:", "n_predict": 128, "image_data": image_data, "stream": True}
response = requests.post(url, headers=headers, json=data, stream=True)
print("Sent request to the server...")
print()
for chunk in response.iter_content(chunk_size=128):
content = chunk.decode().strip().split('\n\n')[0]
try:
content_split = content.split('data: ')
if len(content_split) > 1:
content_json = json.loads(content_split[1])
print(content_json["content"], end='', flush=True)
except json.JSONDecodeError:
breakpython3 llava_api.py --path ./000000039769.jpgSent request to the server...
The image features a large brown and black cat laying down on its side, while another smaller cat is stretched out next to it. Both cats are sleeping peacefully on the same pink blanket. In
addition to the cats, there are two remote controls placed near them, one closer to the left cat and the other nearer to the right cat. The scene takes place on a bed, with the pink blanket
providing a comfortable resting space for these adorable felines.LLaMA Coder
https://github.com/ex3ndr/llama-coder
curl https://ollama.ai/install.sh | shubuntu@ip-172-31-12-212:~$ sudo service ollama status
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2024-01-03 16:19:53 UTC; 2min 38s ago
Main PID: 6125 (ollama)
Tasks: 12 (limit: 38060)
Memory: 5.8M
CPU: 17ms
CGroup: /system.slice/ollama.service
└─6125 /usr/local/bin/ollama serve
Jan 03 16:19:53 ip-172-31-12-212 systemd[1]: Started Ollama Service.
Jan 03 16:19:53 ip-172-31-12-212 ollama[6125]: Couldn't find '/usr/share/ollama/.ollama/id_ed25519'. Generating new private key.
Jan 03 16:19:53 ip-172-31-12-212 ollama[6125]: Your new public key is:
Jan 03 16:19:53 ip-172-31-12-212 ollama[6125]: ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIPFbqdBHvWTLBViNXpEGnVSh2rJ/wwbiObnDXBxM47eT
Jan 03 16:19:53 ip-172-31-12-212 ollama[6125]: 2024/01/03 16:19:53 images.go:737: total blobs: 0
Jan 03 16:19:53 ip-172-31-12-212 ollama[6125]: 2024/01/03 16:19:53 images.go:744: total unused blobs removed: 0
Jan 03 16:19:53 ip-172-31-12-212 ollama[6125]: 2024/01/03 16:19:53 routes.go:895: Listening on 127.0.0.1:11434 (version 0.1.17)
Jan 03 16:19:53 ip-172-31-12-212 ollama[6125]: 2024/01/03 16:19:53 routes.go:915: warning: gpu support may not be enabled, check that you have installed GPU drivers: nvidia-smi command fail>
Jan 03 16:20:33 ip-172-31-12-212 ollama[6125]: [GIN] 2024/01/03 - 16:20:33 | 404 | 744.921µs | 127.0.0.1 | POST "/api/generate"sudo mkdir -p /etc/systemd/system/ollama.service.dsudo sh -c "echo '[Service]' >>/etc/systemd/system/ollama.service.d/environment.conf"sudo sh -c "echo 'Environment="OLLAMA_HOST=0.0.0.0:11434"' >>/etc/systemd/system/ollama.service.d/environment.conf"systemctl daemon-reloadsystemctl restart ollamaMake sure to export 11434 port in your EC2 Instance
Install LLaMa Coder Extension
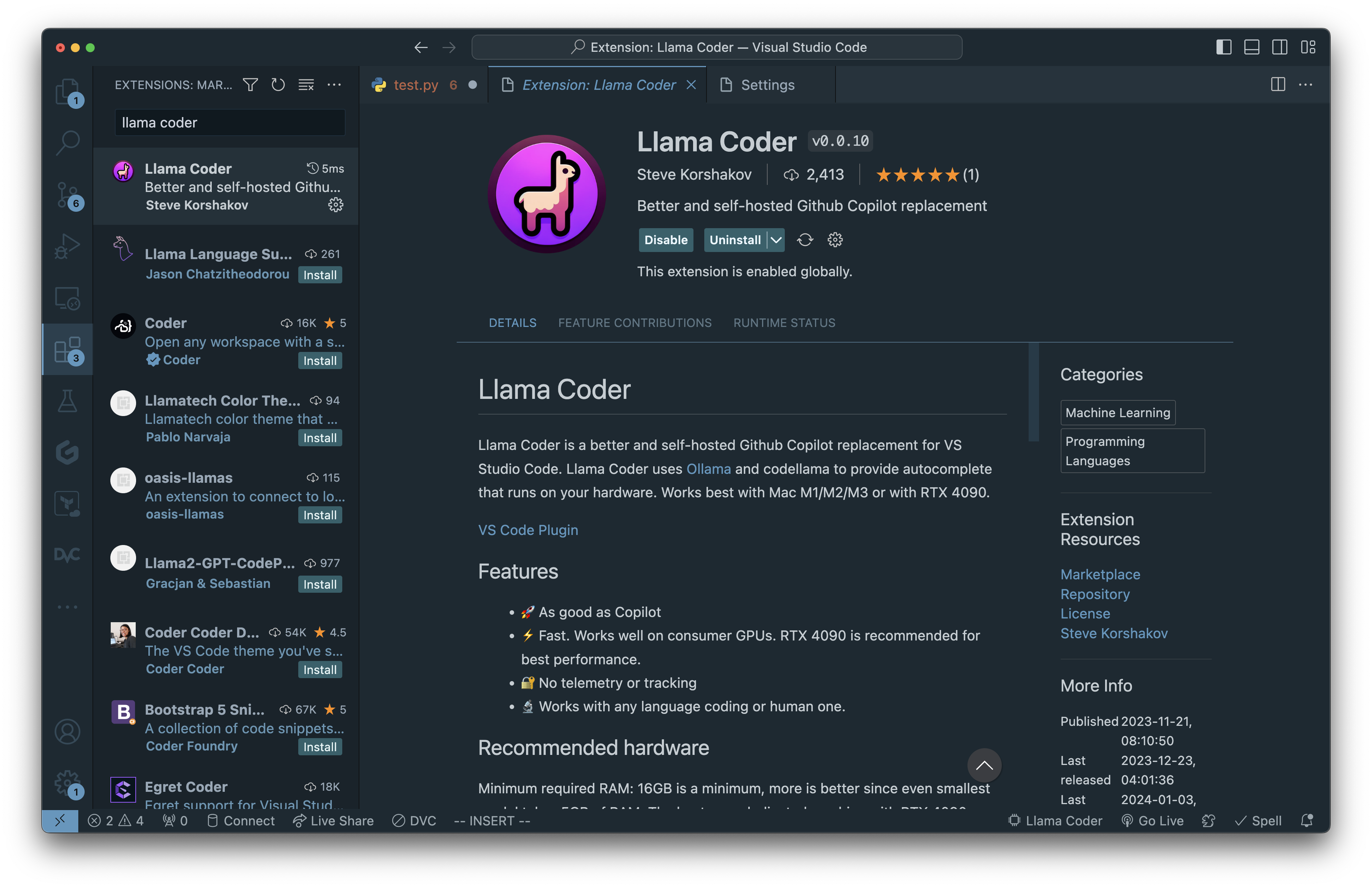
Modify the extension settings to point to ollama instance
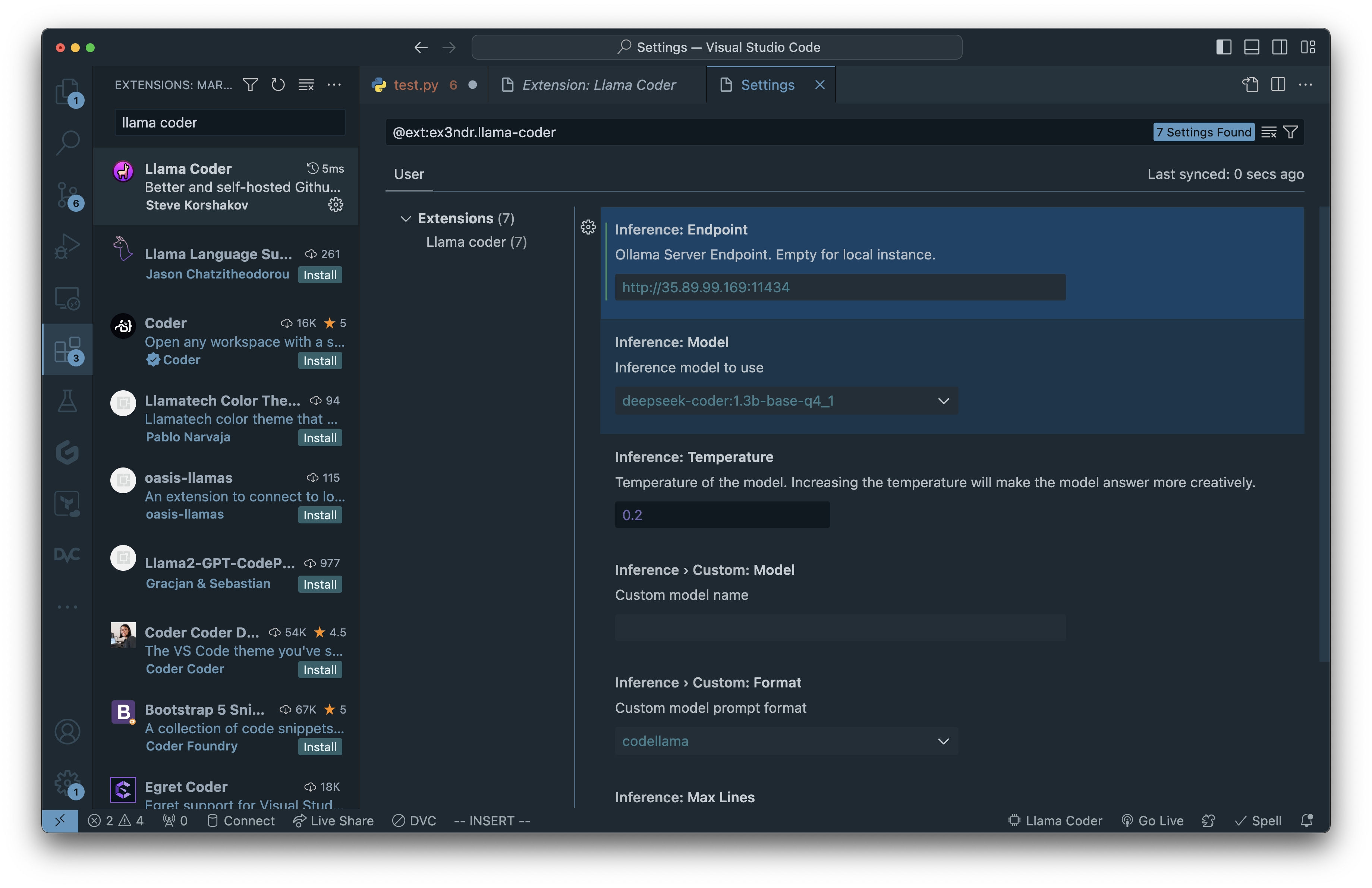
That’s it!
Start Coding
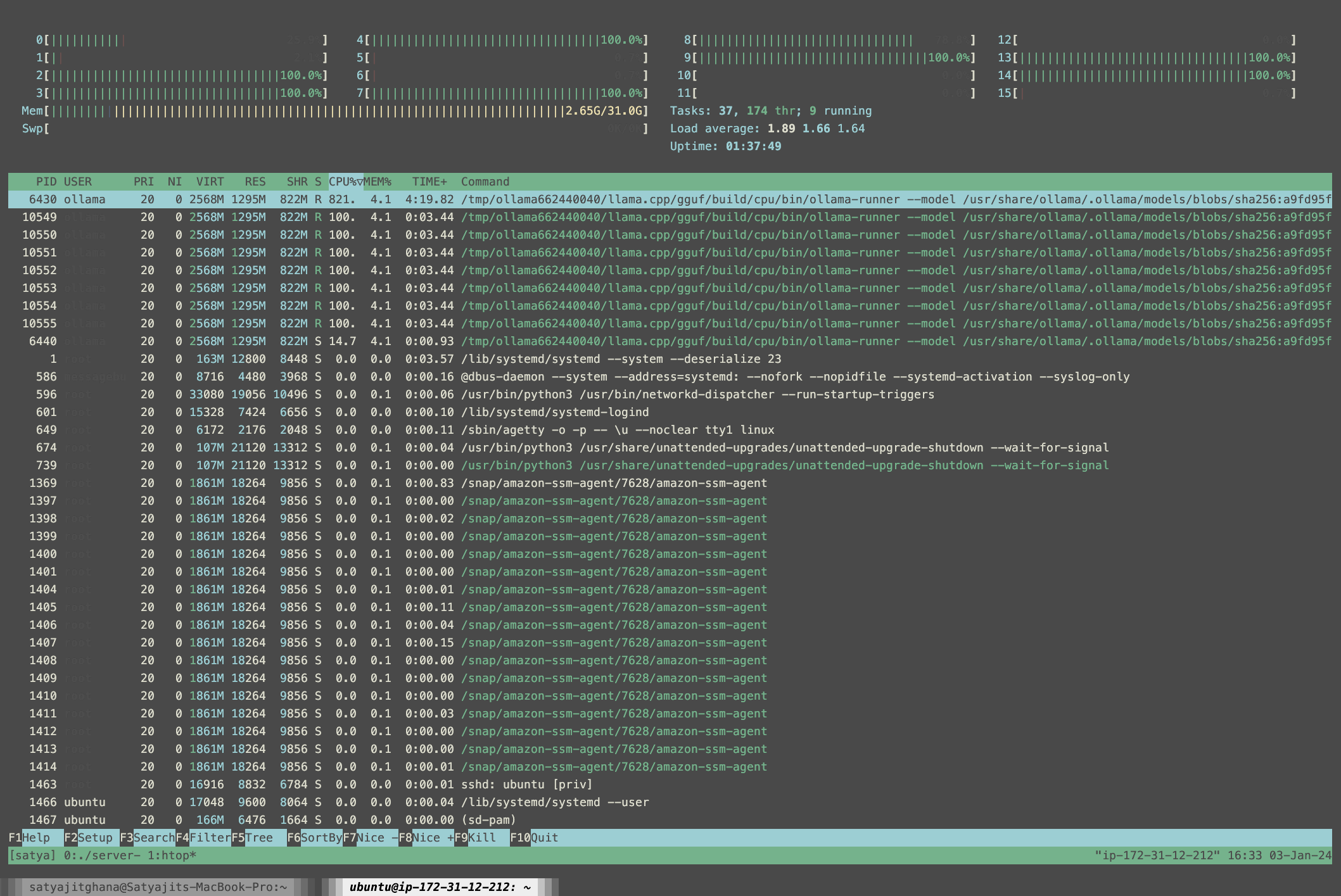
ollama pull codellama:13b-code-q6_KWhisper.cpp
https://github.com/ggerganov/whisper.cpp
NOTES
- MinitGPT4 with GGML: https://github.com/Maknee/minigpt4.cpp
- Stable Diffusion with GGML: https://github.com/leejet/stable-diffusion.cpp
- https://github.com/marella/ctransformers : Python Library using GGML and Huggingface
pip install ctransformers[cuda]from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF", model_file="mistral-7b-instruct-v0.1.Q2_K.gguf", model_type="mistral", gpu_layers=50)
for text in llm("<s>[INST] Write a Python program that prints every even number from 5 to 500. [/INST]", stream=True):
print(text, end="", flush=True)